▍ 摘要
再生医学研究可以为退化性疾病提供新的治疗方案。无论是因为衰老、意外或遗传性疾病而严重损失肌肉的病人,除了服用消炎药和忍受疼痛,都没有可行性治疗手段。因此肌肉再生的研究和临床应用无疑能为很多患者提供一线希望。肌肉再生研究也能为”人造肉“研究与生物机械领域提供重要的参考。
目前,分析肌肉再生机理的最强大武器就是基因组学和代谢组学。但这些方法仍然无法有效捕抓再生过程的复杂时空变化。因此利用干细胞的再生能力开发了器官组织模型,也称为类器官organoids。再结合最新的成像质谱与成像测序技术,便可剖析分子在再生过程中的复杂时空变化。
2019年5月12日青创联盟发起的YOSIA Webinar线上学术研讨会特别推出了“AI+X”科学系列主题:AI+再生医学的前沿发展。在本次报告会上,黄仕强教授将对再生医学,以及有关再生医学与仿生学的交叉领域和发展趋势进行介绍。周少华教授将介绍机器学习与领域知识相结合的“机器学习+知识建模”方法,能够在医学图像识别、分割和解析等许多任务上实现最先进的性能。
点击链接观看视频:https://v.qq.com/x/page/g0881yag7qv.html
▍ 分享嘉宾
主讲嘉宾:
· 黄仕强,中科院动物所研究员,未来论坛青创联盟成员
· 周少华,中科院计算所研究员,未来论坛青创联盟成员
讨论嘉宾:
· 曹楠,中山大学中山医学院教授, 未来论坛青创联盟成员
· 周华,美国阿贡国家实验室物理学家,未来论坛青创联盟成员
主持嘉宾:
· 张璐,Fusion Fund创始合伙人,未来论坛青年理事
▍ 主题报告
黄仕强:肌肉的再生医学和仿生学

世界上有很多很神奇的动物,有些小动物的再生能力特别强,例如涡虫、海星、蝾螈等等,它们都拥有再生整块肢体的能力。对比而言,人类或者哺乳动物的再生能力比较差,但还是有一定的再生能力,例如人类的指甲。

先看肌肉组织。哺乳动物和人类的肌肉再生能力都比较强。1961年Alexander Mauro发现了隐藏在肌肉里的肌肉干细胞,这些干细胞能被激活,而且激活之后能增殖、分化和融合,从而实现肌肉再生。
1961年,对于干细胞领域也是丰收的一年,两位加拿大学者Till和McCulloch,通过辐射实验,证明了骨髓藏着很多造血干细胞。
八年后,1969年,Donnall Thomas经过很多年的努力成功利用骨髓移植治疗了癌症(血癌),为所有血癌患者带来了福音。由于这项成就,Donnall Thomas于1990年荣获诺贝尔奖。

1962年,牛津大学的John Gurdon又取得另外一个很惊人的突破,他完善了SCNT[g1] (细胞核移植),成功从老青蛙的皮肤细胞克隆出多个小青蛙(如上图所示)。所以,60年代初期,干细胞领域取得了很大的突破。可是,至此之后几十年实际进展,直到1996年,也就是30年后,英国另外一位科学家Ian Wilmut才克隆出了绵羊。
虽然哺乳动物能够克隆,但在很长一段时间内,猴子和灵长类动物一直是无法克服的难点。20年后,也就是2017年,中科院神经所,中国的孙强和蒲慕明才完成猴子的克隆。
30年之内,发明SCNT细胞和移植技术Gurdon并没有以此获得诺贝尔奖。直到2012年,他和发明iPSC干细胞重编程技术的Yamanaka,一起获得诺贝尔奖。实际上这是两种不同的细胞重编程的手段,一个是依赖于卵子的发育状态,一个依赖于四个转基因。殊途同归,两者都可以生成多能的干细胞。
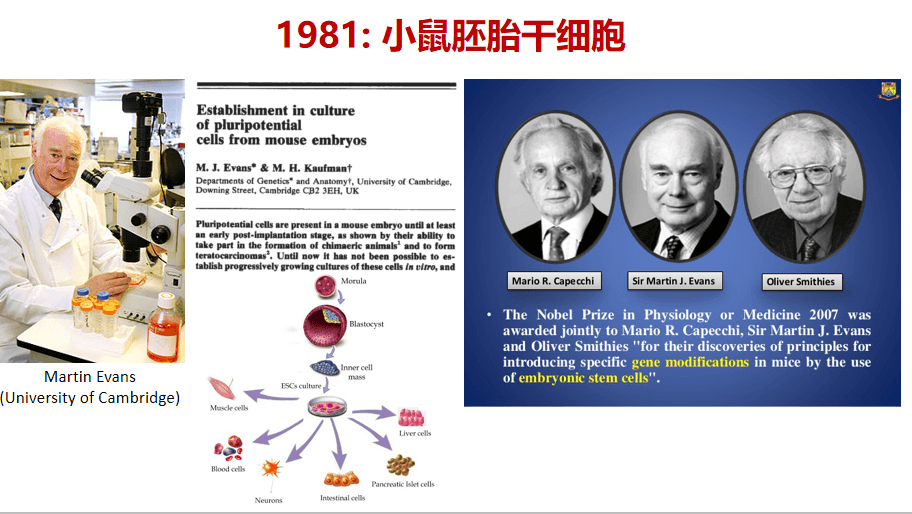
iPSC多能干细胞和胚胎干细胞是同类的,都是属于多能的干细胞,如上图所示,可以看到多能干细胞能分化成胚胎里所有各种不同种类的细胞,也称胚胎干细胞。
1981年,剑桥大学的Martin J. Evans成功的把体外培养小鼠的胚胎干细胞的体系进行了完善,成功的多代数的培养了小鼠胚胎干细胞。
在那个年代,人类的胚胎干细胞移植培养的技术一直没有突破,在1994年,新加坡国立大学的Ariff Bangso才成功修改了培养基,把人类胚胎干细胞培养了两三代,可是过了两三代之后,细胞就分化、凋亡。又过了三、四年,James Thomson才成功取得了突破,他完善了所有培养条件,成功把人类的胚胎干细胞养了超过40代(这已经是永生化的状态),掀起了人类干细胞研究的热潮。

胚胎干细胞研究开始火热,Yamanaka在2006年宣布,他采用基因技术,能把任何普通的细胞变成iPSC干细胞。这一技术瞬间把研究带入高潮,也开创了一个新的黄金时代,例如哈佛的Daley、Hochedlinger、Eggan、MIT的Jaenisch、中科院动物所的周琪院士等等都参与了这方面的研究。
到了2014年,日本正式开展iPSC治疗视网膜疾病的临床实验,但后来因为基因突变的缘故,暂时中断了。iPSC在变成多能干细胞的过程中,非常容易累积基因突变,因而会提升癌症和免疫排斥的风险。
胚胎干细胞因为不需要多次传代的转变过程,且DNA修复功能比较强,基因突变的概率会比较低,其在理论上是比较安全的,所以中科院开展的首批干细胞临床实验是用了胚胎干细胞。但因为iPSC干细胞更容易获取,不需要胚胎,不需要涉及太多伦理的问题,所以还是很多人关注iPSC干细胞。
值得一提的是,不是每个疾病都能像帕金森,可以移植单纯的胚胎干细胞或神经干细胞替换凋零的神经元细胞,从而修复损坏的区域。其他大部分的疾病是因为整个组织或器官衰竭、或失调、或癌症病变而导致。因此下一步就必须用器官组织模型或者类器官进行治疗。这也是目前干细胞领域研究比较热门的方面,现在很多人都可以做出大脑、肺、大肠、肝脏、肌肉等器官模型。有了器官模型,就可以构建疾病模型,分析疾病的机理、进行高通量的药筛、直接把类器官移植到体内,或者替换我们体内的器官。
上述模型如果再配合上最新的CRISPR基因编辑技术,就可以更好地利用器官模型来模拟、效仿、治疗遗传性疾病。再配上时间的进程以及体外条件,甚至可以开始模拟产生衰老症状的疾病,最终达到治疗退行性疾病的远大目标。例如一个MIT团队用大脑的模型,配合APOE4突变与外源环境的代谢条件,就成功模拟了阿尔茨海默症的病发进程。
所以,有了器官模型,研究者可以进行很多新的实验。以肌肉衰减综合症为例,我们利用肌肉干细胞构建了肌肉模型,在体外模拟了肌肉衰减的过程。具体如何构建肌肉模型呢?首先利用了癌症细胞所分泌的因子,进行外源环境的控制,模拟了肌肉在体外衰退疾病的过程。再从3D成像技术去分析肌肉纤维的萎缩。下图中的绿色部分就是3D成像的结果。
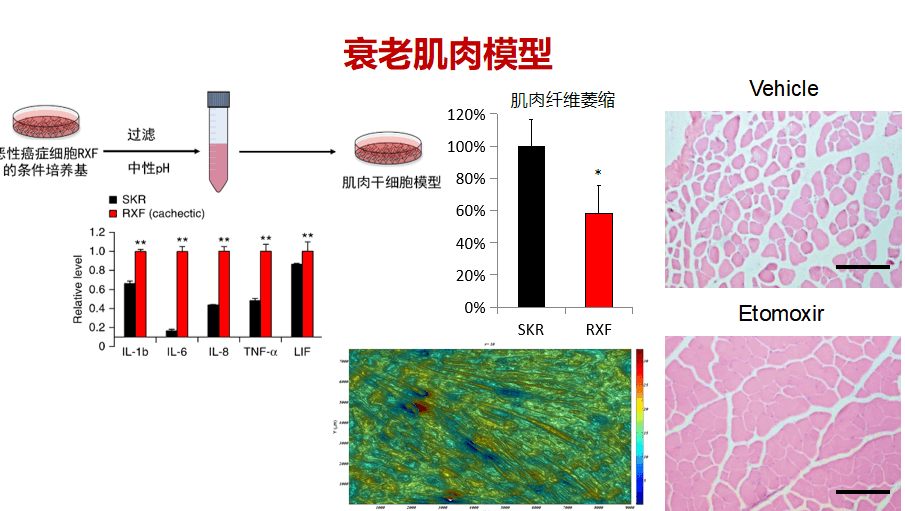
对比正常病人组进行代谢组学分析后,结果发现肌肉衰减症状中的脂肪酸氧化是失调的,下图(中)是分析结果。另外,对脂肪酸氧化进行针对性的治疗之后能促进肌肉再生和挽救小鼠的肌肉衰减症。这篇文章发表于Nature Medicine。

围绕再生、基因和代谢的主题,我们之前还研究了一个类似Healing Factor的干细胞因子(叫做Lin28),无意中找到了一个能促进新陈代谢,促进多种器官再生的基因。此基因在胚胎发育期间表达非常高,但是婴儿一旦出生后,Lin28的表达就会逐渐下降,最终熄灭。我们在成年的小鼠体内再次激活了Lin28基因,结果发现它能促进器官的再生。
我们在Cell发表的文章报道了Lin28基因不止是针对某一种组织的干细胞群,而是针对多种不同组织的干细胞。在小鼠实验中,多种不同的器官,例如皮肤、毛发、手指、肌肉、肝脏等,都能响应 Lin28,显著增加其再生和修复能力。
基于这个发现,我们的研究进一步阐明Lin28促进了成年细胞的代谢率,尤其是葡萄糖的氧化代谢效率,犹如年轻细胞。我们从多种方面研究证明了Lin28能促进类似胚胎时期的代谢状态,从而促进了多种组织的再生。
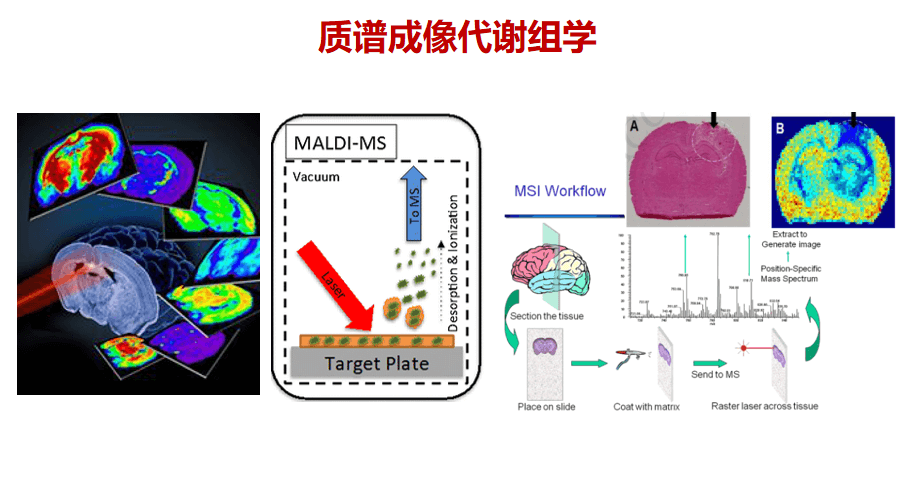
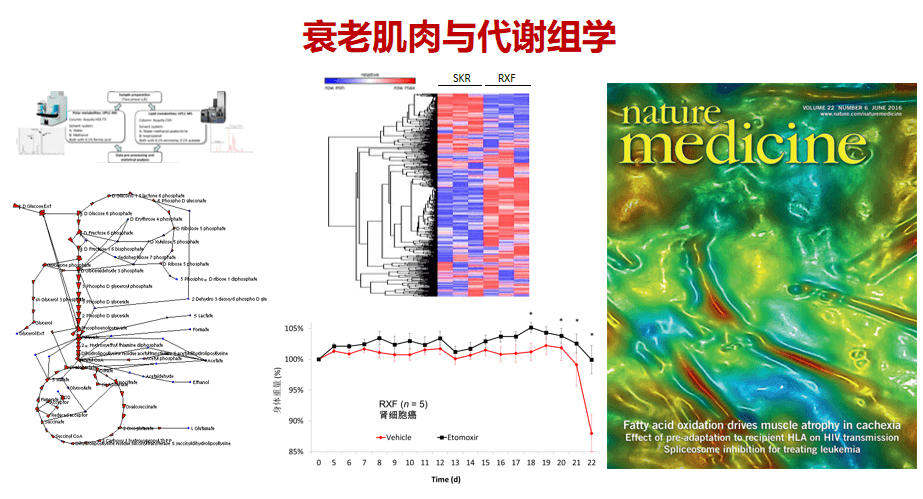
为了进一步了解肌肉代谢的变化,我们开发了质谱成像代谢组学的新技术,能够更深入探讨干细胞的新陈代谢模式及其奥秘。此技术利用激光精准的采集组织切片的每个点以及所有的代谢物离子,每个点都能靠质谱分析出上万种物质,最后能够形成上万种代谢物质的分布图。
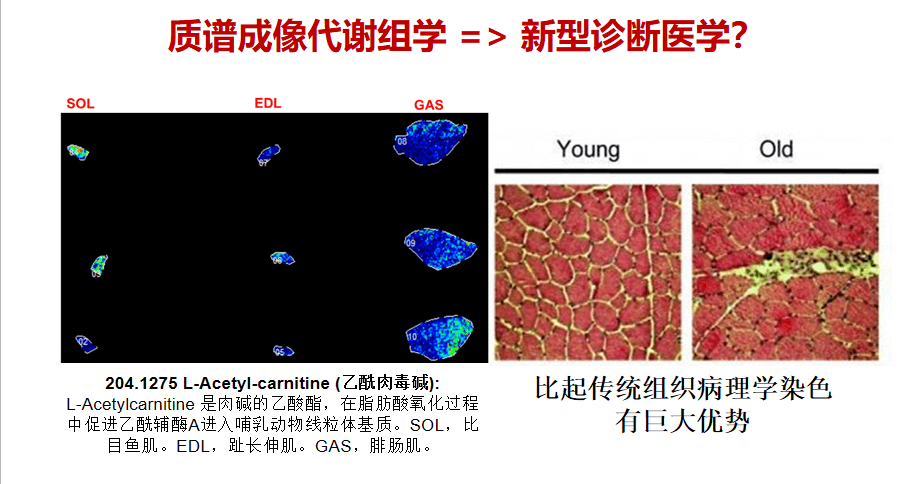
通过进一步改进,我们可用这新技术看到肌肉代谢网络的时空变化。这种新技术能够分析肌肉干细胞与其他细胞群的互动,分析肌肉在衰老与再生过程中的代谢变化,从而找到更特异、更能有效预测衰老与再生的代谢物。我们也在上千种代谢物的对比分析中,看出这门技术比传统的组织病理学染色有更大的优势。
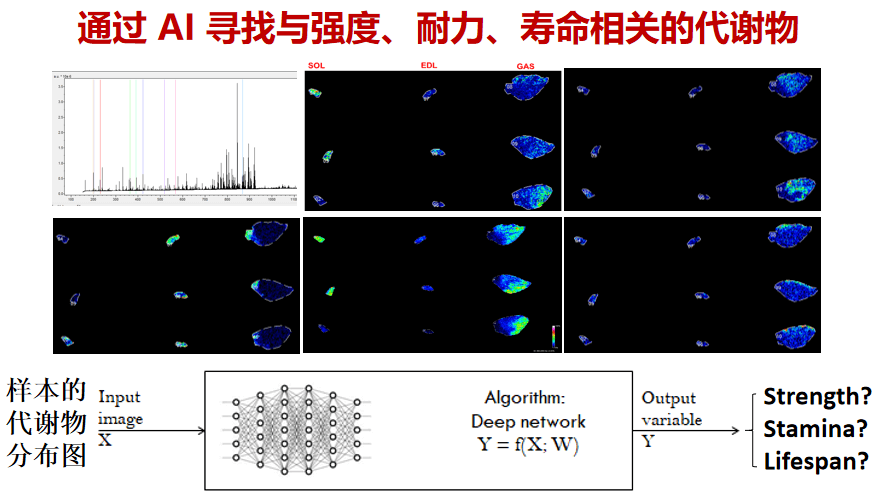
未来,我们也在考虑如何利用海量的代谢物数据与临床信息,希望能通过人工智能去寻找和分析跟力度、耐力、寿命有关的代谢物。在未来的开发工作中,每个相关代谢物都有望变成一个抑制衰老、促进再生的新型药物。
▍ 周少华:AI与医学影像
这次报告是分享在医学影像分析领域,如何利用机器学习和知识建模进行更好的分析。先谈一下我对AI的理解:首先有一个图象,然后从图象中把知识提取出来,其中,知识有很多很多种,我先介绍两种,一种是关于解剖结构,另一种是关于对疾病的理解,现在特别火的辅助诊断,则属于这一类。
AI技术带来的好处主要有两方面,一方面是对成像设备本身有很多好处,让成像更加个性化,还可以帮助医生来进行更加结构化的阅读,使他的诊断流程更加有效;另外一方面可以用来支持进一步的手术和治疗:规划手术和预测手术是否成功。
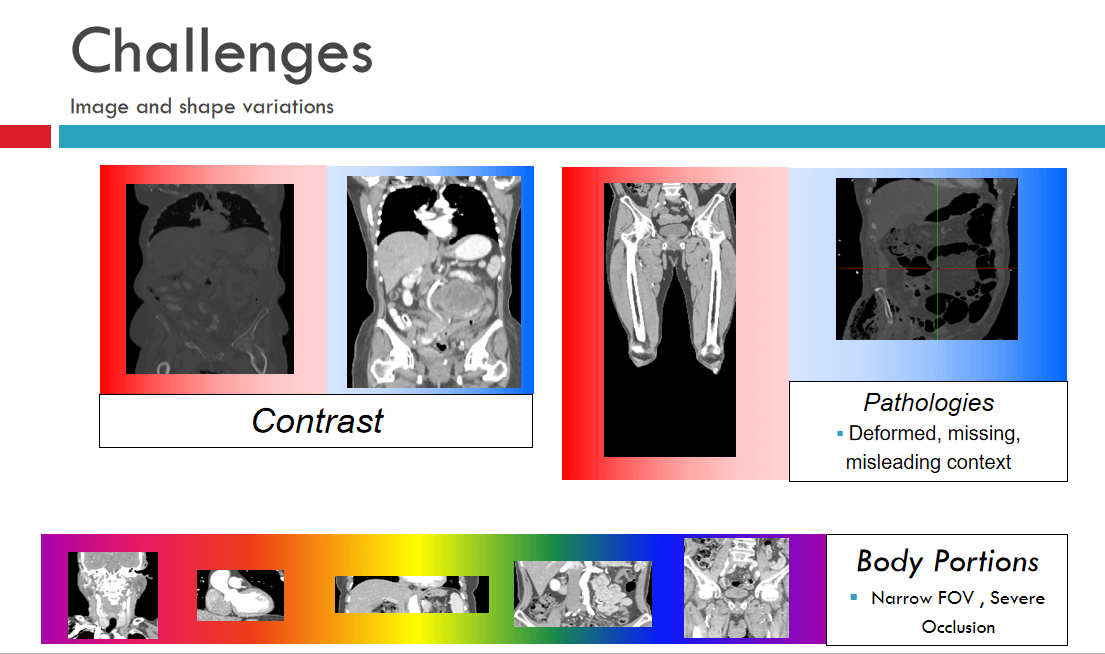
然而要分析一张图象,达到非常高级别的理解不是一件容易的事情,举例而言,上图左的CT是没有打造影剂的图片,右边是打了造影剂的图片,造影剂的目的是为了观察血管更清楚,但是从解剖角度来看,无论是不是打了造影剂,还是没有,都是同一个解剖结构,算法都应该能够充分理解。
同样的,疾病会造成图象不同的变化,分析算法必须充分理解到这些变化。当前还有一个挑战是:医学影像往往不是全身扫描,大多数只是一个半身的或者很小的一段。但这时候如果要提取解剖结构,很可能只能提取心脏的部分结构。
还有比较难解决的问题是:要达到使用级别的AI系统,必须要很鲁棒,必须要很准确,诊断要迅速。但是当前知识的复杂性制约了AI系统的使用,例如,按照放射科的知识库,疾病大概有17000多种类别。所以,如何构造实现全面辐射的辅助诊断系统,在目前阶段还是很大的挑战。
但在医学影像方面,目前有两个突出的机会:第一是数据,第二是知识。关于数据,医院里每天一台机器上可以扫描几百个病人,这其中带来的数据是海量级别;关于知识,当前的解剖结构体系,各种疾病知识定义都已经很完善。
由于机器学习是从大数据里抽取特征,进行描述问题。知识模型是基于已有的知识,把它给数学化、算法化。因此,研究最新的机器学习方法,结合知识模型,从而分析医学影像便成为了可能。
机器学习分很多种,例如有监督学习,无监督学习,目前用深度神经网络作为载体方式已经成熟。而知识模型,相对来说是比较被忽略的方向。
医学影像本身是从感知器“导入”,可以简单理解成为一个照相机,照相机通过一些物理原理实现了影像,因此物理上的原理知识也可以利用来作为算法的一部分。
关于机器学习和知识的结合,我举一个例子。在深度学习之前,有一个算法能够帮助医生从CT图像里看肋骨,此算法能够把肋骨的中心线给检测出来,这样就可以在电脑里,把肋骨展平了。
显然,这个功能可以帮助医生更好、更快的阅片和临床研究。
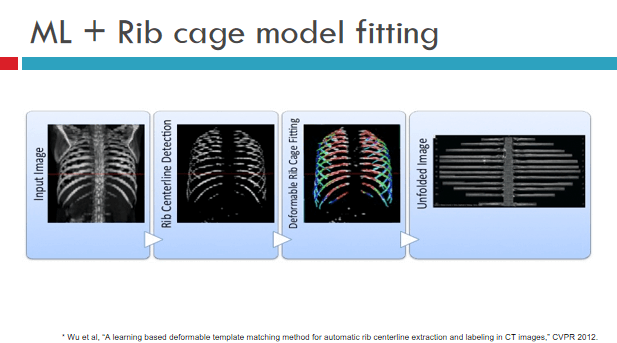
上图是简单的机器学习和知识模型结合的例子,左边有一个输入图象,高亮的地方代表骨头,,通过机器学习的方式,我们学习了一个分类器,把肋骨的中心线“区分”出来,作为正样本,其他别的像素点都是负样本。学了分类器之后,相当于肋骨的中心线基本上能检测出来。我们同时又知道这是一个肋骨,所以建立了肋骨的模型,可以把这个模型匹配到中间第二个检测到的肋骨中心线上去,匹配完了之后,相当于把肋骨的所有中心线都检测到了,就可以在电脑里面把它展开,得到最后展开的如上图所示。

另外,如果存在上下文的知识,也能够帮助改进算法。例如上面两张图片,对于第二张,我们非常能够清晰的找出它的眼睛在哪里,对于第二张图片,如果想明确分辨眼睛在哪里确实要下一些功夫。为什么两张图片的区别那么大,原因在于第一张图片的上下文信息比较丰富。所以,有很强的上下文的知识,就可以帮助我们训练出非常好的算法。
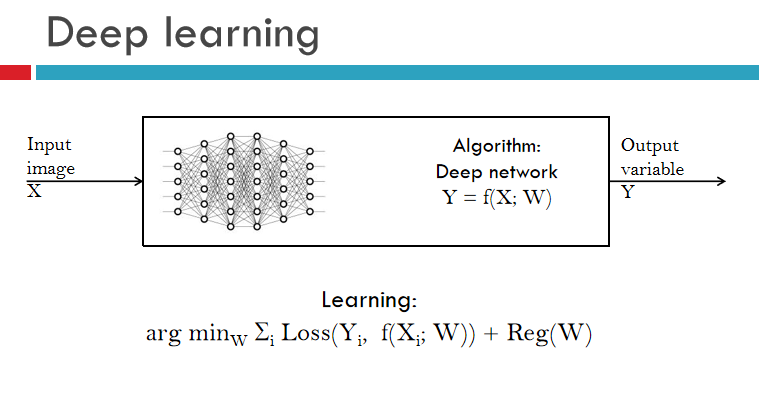
下面详细讲讲深度学习算法。本质上,深度学习是一种机器学习的方法,(上图)左边有一个输入图象,(上图)右边是想要学习,或者想要推测的输出,中间通过深度网络进行训练得到映射。
在学习的过程中,需要有训练样本,需要定义函数,来学习参数(W)。学完了,整个深度学习网络就算学成了。
不同的人对深度学习有不同的理解,有的人认为它会改变一切,但对我来说,最深的理解有两个方面,第一是神经网络是一个超强记忆力的机制。

如上图所示,图片里面有很多曲线,曲线代表训练的错误,蓝色的线条(true labels),随着训练的时间变长,average loss很快就会降到零。再比较看一下红线,红线代表随机的labels,它的average loss,经过长时间的训练,也会降到零。
因此,我们可以明确,这种结果的原因是:网络把这些训练样本全记住了,否则训练的错误不会是零。因此,这个网络可以记住很多东西,哪怕你给它很多数据,它都可以记住。哪怕你给它标识是错误的,它也记住了。
第二,神经网络本身会有很多参数,基本上现在一个比较大的网络可能达到千万级的参数,或者上亿级的参数。
基于以上,神经网络的性能提升也有两个思路:1、增加数据,然后看情况增加网络容量;2、结合现有的知识。知识的融入可以从三方面入手,输入端、输出端、中间的算法。
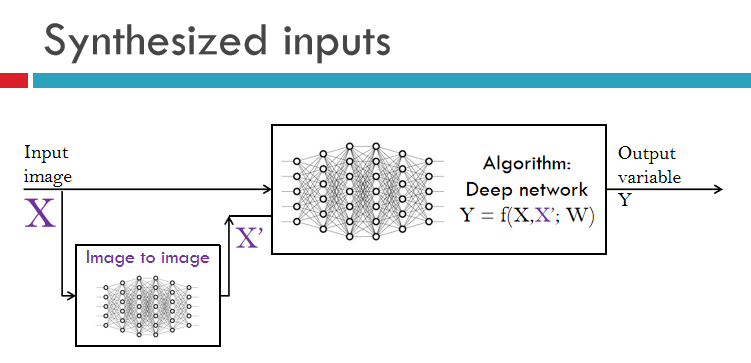
从输入端如何操作?一个简单的例子,就是尽量要用更多的输入信息,比如说你有输入的图象X,我甚至可以通过一个神经网络来单独学习,把X变成另外一个X',得到了两个不同的影像模态,然后把这两个模态输入到神经网络当中,然后进行预测Y。
在输出端融合知识,首先可以进行多任务学习,或者输出表达可以用更新的表达,或者输入端可以引入更多的新知识。多任务的意思很简单,要学习Y,但是正好还有Z需要解决,因此你可以通过网络学习,让它预测Y和Z,通常会发现预测Y的能力其实是变强了。
这里有个直观的解释,多任务处理相当于网络见多识广、触类旁通,而任务Y和任务Z之间会有一定的关联,其中的关联性是帮助了预测Y。
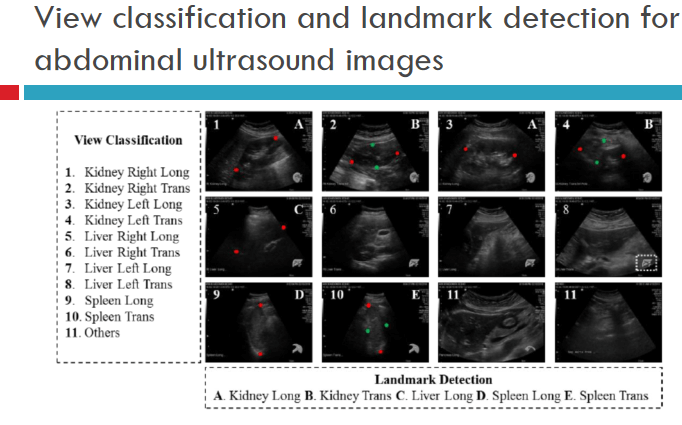
如上图所示的例子,此项目有两个任务,左边任务是切片分类,在腹腔超声的二维图片识别器官;第二个任务是在某一些标准切面里用关键点检测尺寸(例如识别肾脏的大小)。因此,我们训练一个神经网络,能够同时输出判定切片和检测关键点。
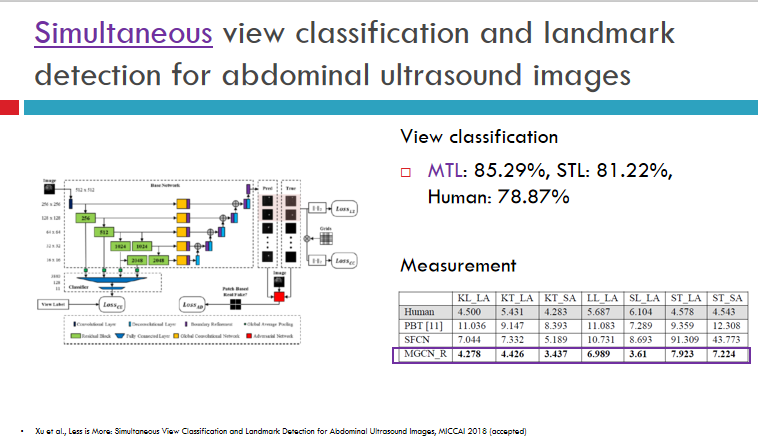
网络在多任务学习中的准确率如上图所示,切片分类效果来看,准确率达到85%。高于81%的单任务准确率。关于尺寸测量,上图表格里显示了网络预测的测量结果和真正的测量结果的差别,表格的最后一行显示,其错误率非常低。
关于表达的问题,其实关键点的表达有很多方法,一种是直接表示出关键点的位置,另外一种可以输出关键点的最高值,这种表达是非常常见的一种表达,也挺有效,但是也有一些可以改进的地方。
例如对于一些点,其实只知道它不是关键点,但没有对关键点的位置提供任何帮助。因此,我们定义了一种新的表达方式,通过每一个像素点位置,从而得知想要检测的关键点的方位。引入这种表达方式,就等于利用上下文信息,从而更有效地帮助关键点的检测。
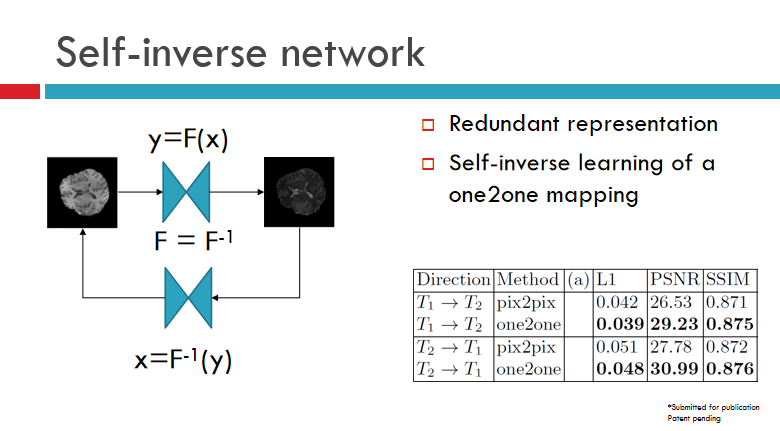
现在介绍知识融合三个部分,如何在设计网络的时候利用知识。假设有两个任务T1、T2,通过算法学习可以达到的效果是:从T1可以生成T2,即我们学习一个深度网络,可以让它变成另外T2。同时,也可以学另外一个网络,让它从T2反变回T1。
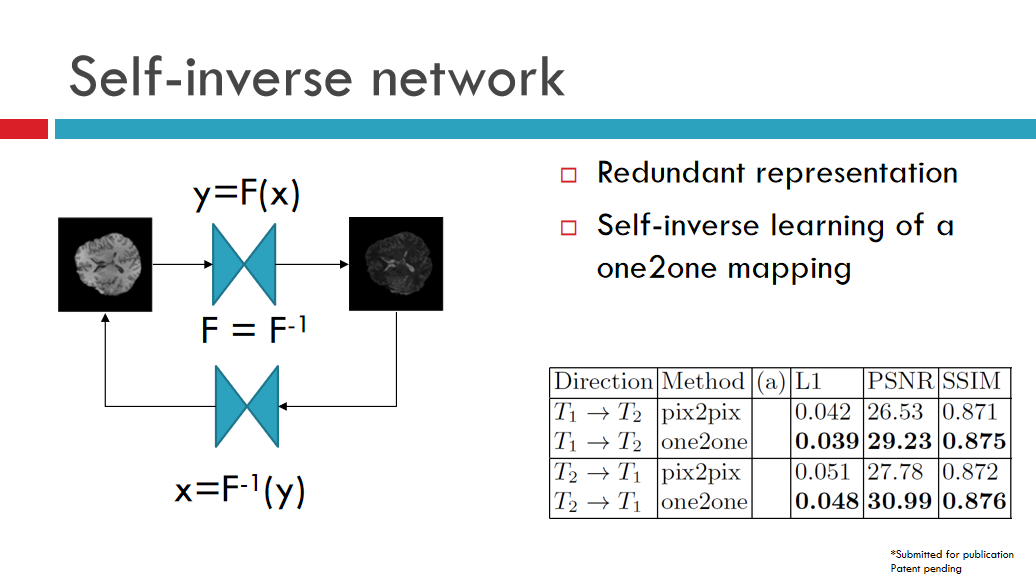
其实,网络本身存在很多冗余度,毕竟,一个网络本身可能具有千万级的参数量,这中间的表达是有很多冗余度的。于是,我们做了一个简单实验,学习一个网络,正网络F和逆网络F-1(这俩同一个网络)。如此便能保证此网络是可逆的,无论是T1还是T2,都可以生成另外一个模态。自逆网络实际上是利用了网络本身的冗余度,增强了其表达能力。
 。
。
这是利用网络冗余度的另一个实验,这个情况下有几种不同的任务,第一个任务可能是在核磁上进行脑结构的分割;第二个任务是用CT作为输入,从而进行肝脏的分割;第三个任务,可能还是CT,但是别的模态。在网络设计的时候,其实在中间进行了简单的探索,即探索能不能学一个网络,把多个机器学习的任务解决,而不仅是针对一个任务单独学习一个网络。如此之后,我们发现针对六个任务,只是用了原来六个单独网络4%的参数量,但是效果基本相同。
总结一下,本次报告主要分享了三个主要的信息。第一,AI本身在医学影像里有重要的趋势;第二,机器学习和知识模型融合目前是非常好的研究方法;第三,即使在深度学习时代,也可以恰当的引入知识,从而让系统的性能更加优秀。
▍ 跨学科讨论
AI模拟和理解疾病走到哪了?
张璐:如何结合器官组织模型与代谢组学、基因组学甚至现在非常火热的话题AI技术,来更好地模拟和理解疾病,这些方面有没有看到一些比较有意思的进展,或者说我们可能要关注的技术发展点?
黄仕强:之前研究干细胞都是纯粹去看干细胞群,相对来说分析方法都比较简单。现在整个领域都开始步入下一个研究阶段,开始看类器官或者器官模型方面的研究,这时候就不只是看干细胞本身,还得看干细胞周遭的环境以及其他的细胞,所以是一种复杂的3D结构。到了这种阶段我们必须更多地依赖于类似成像一样的分析手法,才能一次性的看到每种细胞不同的种类在哪里分布,它们跟哪一些其他细胞有什么互动,每一个不同的细胞群呈现什么样的表型。运用AI技术去分析代谢组学这些海量成像的数据,去了解跟肌肉衰老或者肌肉再生相关的代谢物的研究仍处于一种初步的阶段,需要我们关注。
曹楠:关于成像的问题,AI就我理解更多是计算机算法上的事情,运用3D技术我们可以得到很多更复杂的信息,但是我们怎么去把三维的东西进行更好的成像,去量化,把这些信息提取出来,然后用AI技术去分析。比如说刚刚提到的高通量药物筛选,我们要找到几万个化合物或者是小分子,不太现实一个一个去看,这可能需要更多领域的科学家在一起合作讨论交流,才能更好地推进对整个技术科研认识以及新的药物的筛选。
黄仕强: 我同意曹楠老师说的,尤其在药筛方面,每一个器官组织或者每一种干细胞都有多层面的表型,目前成像仪器硬件以及软件方面都还没达到我们所需要的要求。
多领域融合,人造肉以及生物机械该怎么走?
张璐:如何结合刚才各位老师分享的器官组织模型以及材料科学工程、电子工程包括现在另外一个很火热的话题3D打印去构建人造肉以及生物机械?
周华: 这个问题问的非常好。人造肉在全世界已经有过几年时间了,从最早欧洲的国家,包括美国,包括现在的一些饮食机构,也介入其中,这一块需要谨慎观察一下。生物机械仿生学这一块,以及3D打印、材料工程科学方面,我认为是一个非常好的发展。但是也带来了一些问题,包括3D成像的过程,其实里面好多材料的开发,包括整个架构的开发都需要很多真正意义上3D实时原位成像的东西来辅助。还有周少华老师讲的海量的数据,其实需要很多类似于在医疗领域用的AI的东西来辅助对于3D的数据进行分析,这值得很多年轻的学生包括有交叉学科背景的学生来投入进去,这是我分享的观点,谢谢。
A:周少华:其实我们现在技术发展可能还没达到很高的水准,已有的数据是少量高维的,在数据量没有特别大的情况下,目前深度学习这个技术还没有达到一个很好的水准。最终想学一个网络辨别出来这个可能是一个疾病,或者是没有疾病,中间输入的变化因素是特别多的,如果说没有足够多的样本支撑的话,很难学的很好,这个其实也是需要我们做很多努力,我个人觉得目前可能这种深度神经网络的框架还需要更进一步的完善才能达到。
道德伦理,潜在问题在哪?
张璐: 请问除了技术之外,从社会架构、道德伦理层面上,各位老师觉得再生医学和基因编辑比较,谁更容易让社会接受,更容易获得比较好的法律层面上的认可进入商业化呢?除了讲的基本伦理道德,有没有一些可能潜在会出现的问题,我们可能需要去提前想到的?
黄仕强:我觉得从技术的角度,有一些病症是天然性的,本身与生俱来就遗传的疾病,可能用基因编辑去解决会更有效,有些病是后天产生的,而且只影响一整个器官部位的话,用再生医学的技术来解决这方面的问题风险会比较小一些。无论从效益或者是从伦理的角度,我更倾向用再生医学的技术。
周华:比如说讲现在人都有用假肢,当然不是再生出来的假肢,是体外的一个假肢,我觉得再生医学如果能再生出这么一个肢体,这么一个功能,我感觉就再生医学来讲伦理上似乎没有什么风险。
曹楠:再生医学伦理问题可能更多的是赋能,我们人本来没有这么强的再生能力,然后我对这个机理研究的非常清楚了,我把这个功能表达在人身上,更多的蛋白会表现出更好的再生能力,会变成超人一样,可能这就涉及到伦理的问题。
张璐:现在人工智能和再生医疗,和各方面医疗都有结合,其实也照样体现社会伦理的讨论?
周少华:我个人觉得至少目前的人工智能技术离我们能想象的要改变人类各方面,实际上还真的是差很远很远。人工智能现在能够替代人类做的事情,很多都是单任务的事情。
周华:我也很同意,替代的其实就是非常重复性,低智力投入的机械性劳动,其实这个东西本来随着人类社会的发展就会被不断淘汰的,即使没有AI也会被淘汰。
(全文结束)