▍摘要
过去10年,以深度学习为代表的人工智能技术深刻影响了人类社会。但人类要进入真正意义上的智能时代,需要更强大的智能技术。而向人脑学习、借鉴人类大脑的智能产生机理,被认为是一条非常值得期待的道路。反过来,AI技术也在深刻改变着脑科学的研究方法。在“观测脑”手段不断变革的基础上,AI技术为脑科学提供了越来越强大的分析、展示和科学发现手段。
此次“AI+脑科学”Webinar将汇集脑科学家和AI技术专家,从“Brain Science for AI”和“AI for BrainScience”两个视角进行前沿讨论,以期能碰撞出创新的思想之火花。
点击链接观看视频:https://live.polyv.cn/watch/1315432
▍分享嘉宾
主持嘉宾:山世光,中科院计算技术研究所,未来论坛青创联盟联席主席
主讲嘉宾:
胡晓林 清华大学计算机科学与技术系副研究员
唐华锦 浙江大学计算机学院教授
吴华强 清华大学微纳电子系教授、副系主任
讨论嘉宾:
毕国强 中国科学技术大学神经生物学与生物物理学系主任,合肥微尺度物质科学国家研究中心集成影像中心联合主任
毕彦超 未来论坛青年理事、北京师范大学认知神经科学与学习国家重点实验室、IDG/麦戈文脑科学研究院教授、长江学者特聘教授
吴思 北京大学信息科学技术学院长聘教授,IDG/麦戈文脑科学研究所研究员
▍主题报告
《神经形态计算机》—唐华锦
人物介绍:唐华锦教授分别于浙江大学、上海交通大学完成本科和硕士学习, 2005年新加坡国立大学获得博士学位。2008-2015年于新加坡科技研究局资讯通信研究院担任Robotic Cognition实验室主任,2014年起担任四川大学类脑计算研究中心主任,目前为浙江大学计算机学院教授。主要研究领域为神经形态计算、类脑智能芯片、智能机器人。获 2016年度IEEE TNNLS杰出论文奖、2019年度IEEE Computational IntelligenceMagazine杰出论文奖。担任/曾担任IEEE TNNLS、 IEEE Trans. on Cognitive and Developmental Systems、Frontiers in Neuromorphic Engineering,NeuralNetworks等期刊的Associate Editor,担任国际神经网络学会(International Neural Networks Society)理事及评奖委员会成员等。

今天的演讲主题是《神经形态计算:开放问题的探讨与展望》,整体内容分为四部分:首先简述计算机与大脑的区别以及大脑对开发更加新型智能计算机的启示;接着讨论关于神经形态计算机的必要组成以及介绍大脑如何完成各种计算任务;之后介绍目前算法的进展以及硬件方面设计的成果;最后总结和展望。
计算机与大脑
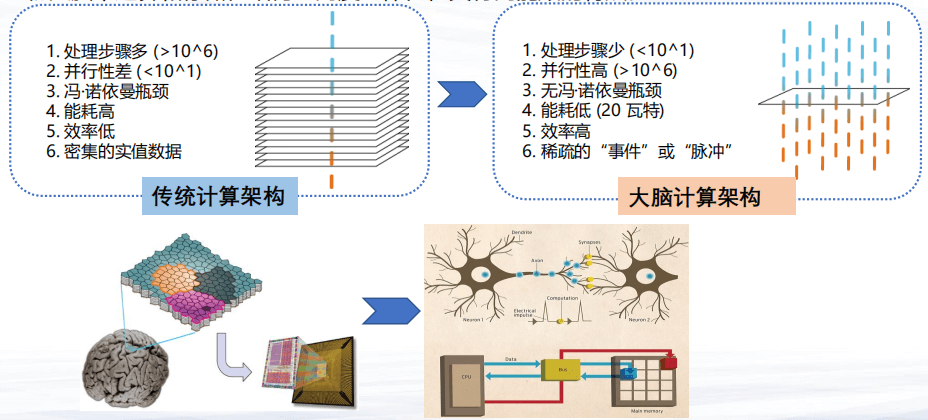
目前的计算机体系是基于冯·诺伊曼架构,这种架构已经引领了计算机科学技术几十年的发展。
但是,随着技术的发展,冯·诺伊曼架构的一些制约也越来越明显。例如,基于冯诺依曼结构的传统计算架构运行效率受到了IO性能的制约,深度学习等算法凸显了冯·诺伊曼体系结构的瓶颈,数据读写严重降低了整体效率。
破除冯·诺伊曼架构的制约,一个重要的思路是像大脑学习。首先,大脑处理的步骤少,运行速度快;其次,由于突触和神经元同时可以做激发和存储,所以不存在冯·诺伊曼架构的I/O的吞吐带来的瓶颈;再者,大脑的计算能耗非常低,只有20W左右,因此其计算效率非常高。
值得一提的是,冯诺依曼架构的计算机和大脑在数据处理方面,存在着显著的不同:计算机处理大量的实值数据,大脑神经元处理的(或者说编码的)都是稀疏的事件(或者神经科学称之为脉冲)。
因此,构建一个非冯·诺伊曼体系的新型智能计算机体系,不仅是计算机科学,也是计算机工程以及硬件芯片发展的一个重要方向。在未来,随着新的计算体系结构以及硬件方面的实验发展,新型智能计算机体系可能会带来新一代的人工智能算法硬件以及架构上的新突破。
神经形态计算机的必要组成
其中,新型智能计算机体系指的是向大脑“借鉴”的神经形态计算机。而借鉴主要来自四个方面:
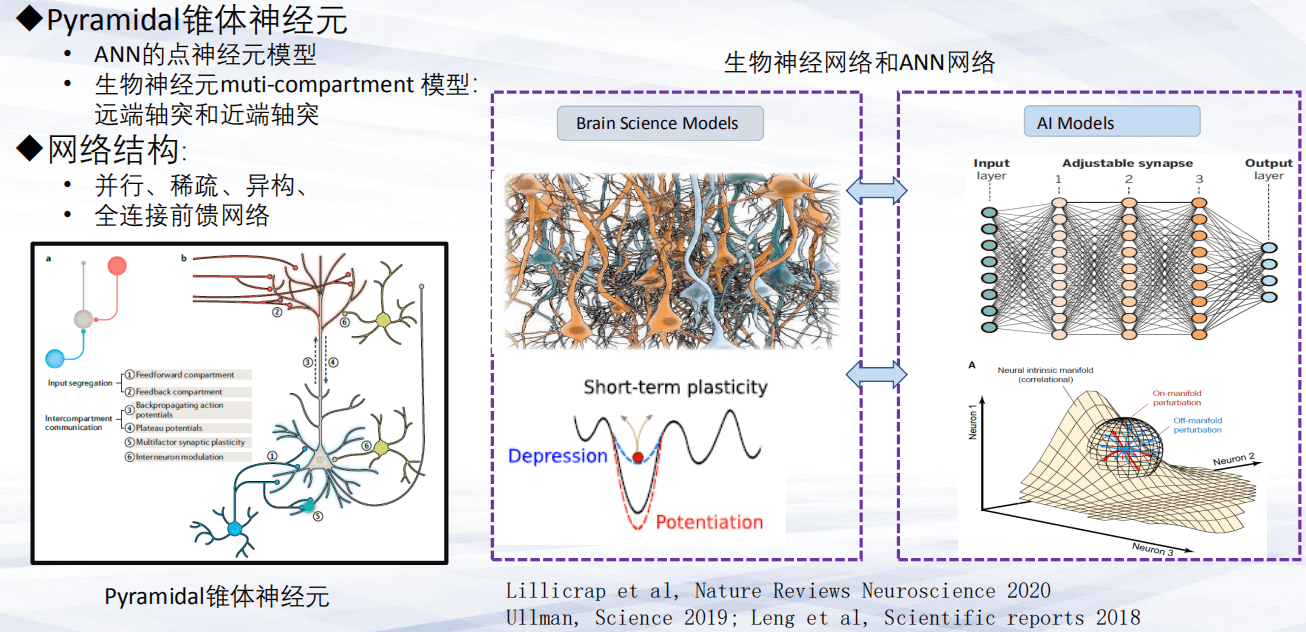
第一,网络结构。生物神经元有多种类型,以锥体神经元(Pyramidal神经元)为例,它是多个环节、多个部件组成的复杂的神经元模型结构,包括轴突的远端和近端,能够对生物神经元进行输入前馈和反传。值得一提的是,生物神经元的输入前馈和反传发生在神经元的不同部位,对于I/O来说做了充分的简化。从网络结构的角度考虑,大脑存在着大量稀疏的异构的连接结构,目前ANN(人工神经网络)主要依赖的深度网络是前馈全连接的网络结构。
不同的网络结构处理的实际方式也有显著不同。基于深度网络的空间算法,往往采取一个全区的优化函数来达到最优值来调解;而对于生物神经网络来说,由于存在大量的局部连接以及远程连接,有丰富多样的突触可塑性,可以更加灵活的调整神经元之间的连接来完成对目标函数的优化。
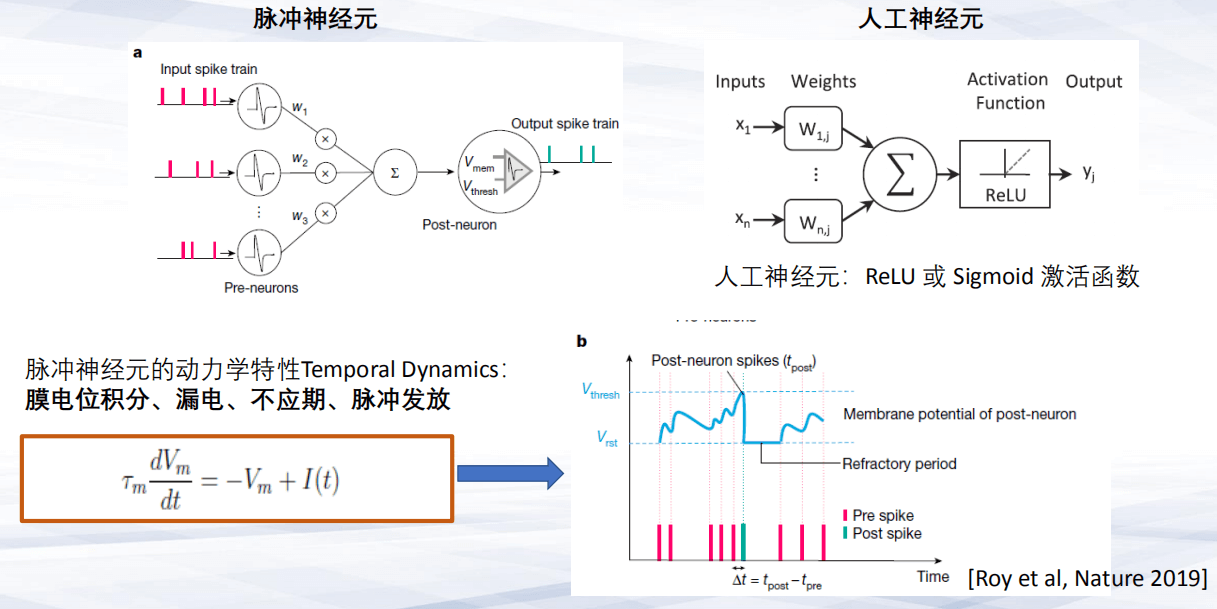
第一,大脑采用的是具有生物特性的计算模式。人工神经元不需要考虑输入的时间特性,输入是一个实值,具体例子如:ReLU函数或者Sigmoid激活函数支撑的非线性结构。但是对于生物神经元来说,它不仅采用了输入输出的映射,还具有四个典型的时间的非线性动力学,一是膜电位积分,二是漏电效应,三是不应期,四是脉冲发放。这四个动力学会导致脉冲神经元输入脉冲编码的不连续性,以及输出脉冲的不连续性。
第二,信用分配问题。信用分配在人工神经网络里常常说成是优化算法,最典型的一个优化算法是误差反传,就是梯度下降算法。梯度下降算法存在一个误差传输问题,即要求前向和反向权值要完全对称。这也是典型的ANN(人工神经网络)的学习模式以及处理方式。
第三,生物神经元与ANN的信用分配机制完全不同。神经元之间依赖于脉冲发放时间,导致他们可以采用基于脉冲时间的学习方式。最典型的在神经科学里面应用非常广泛的STDP(脉冲时间依赖的突触可塑性),基于脉冲时间前后发放的时间差来调整权值,实现局部的无监督学习。
此外,也可以通过设计实际脉冲序列和期望脉冲序列之间的序列差来有监督式的学习和训练发放脉冲。另外可以把每个神经元和突触都当做一个智能体,发放脉冲或者不发放脉冲作为智能体的动作,来构成一个强化学习网络。这样可以实现更加灵活并且生物性更强的一种学习算法。
另外可以把每个神经元和突触都当做一个智能体,发放脉冲或者不发放脉冲作为智能体的动作,来构成一个强化学习网络。这样可以实现更加灵活并且生物性更强的一种学习算法。
第四,学习与记忆的融合。在前馈网络里,权值训练完之后,当新的任务进来,往往权值会被覆盖,但是在生物神经元里面,有大量的专门负责记忆的细胞,比如海马体中存在各种记忆细胞,可以记忆熟知的场景,对这个空间进行编码。所以“借鉴”皮层-海马等脑区,可以实现神经元大脑对外部输入的表达,从而构成一个基于学习、基于融合的认知计算。
具体而言,如上图右侧所示:对皮层以及海马体主要微脑区的神经电路结构,基于这样的电路结构,可以实现基于海马体的联想记忆、持续记忆以及对空间的记忆模型。
算法与硬件实现
有了基础架构,那么算法以及硬件方面设计的成果进展如何呢?下面介绍五个方面的工作:
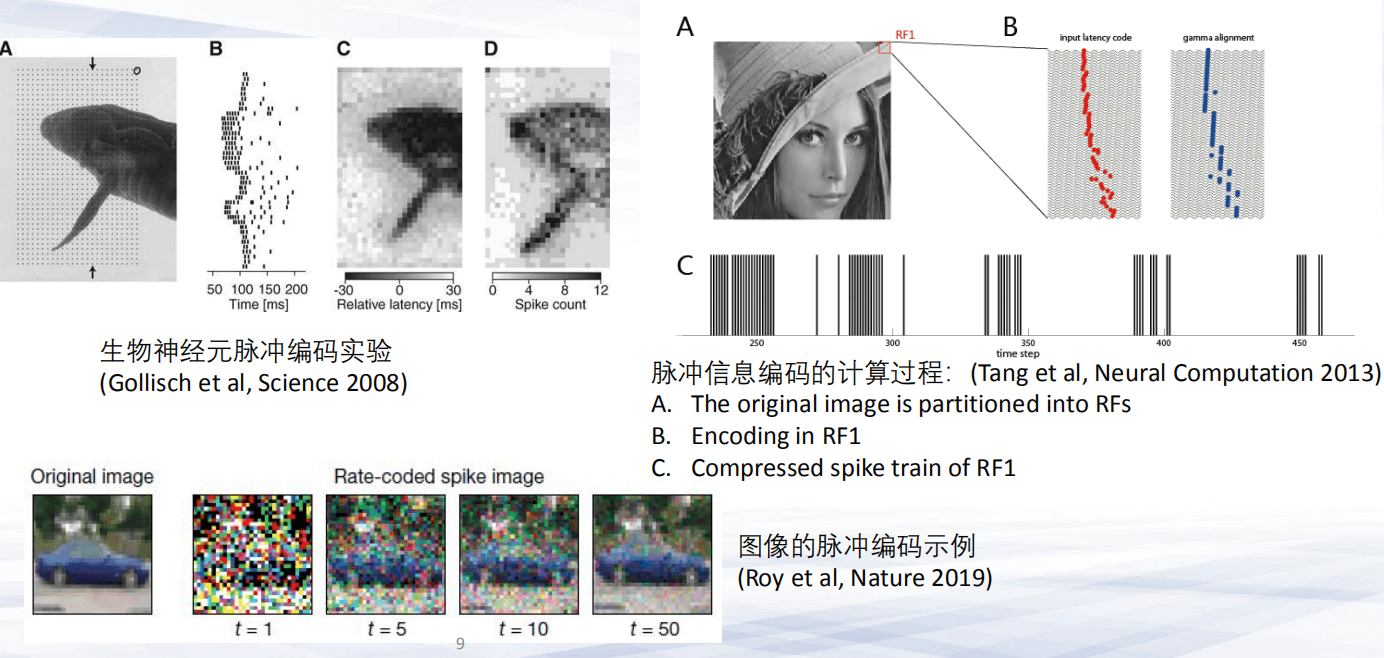
第一,信息的编码。采用的基本思想是:把输入信息经过脉冲神经元的编码转变成一系列的时空脉冲信号,可以对输入信息进行编码以及重构。最新进展,如上,编码神经元的算法的图示( Nature 2019)。
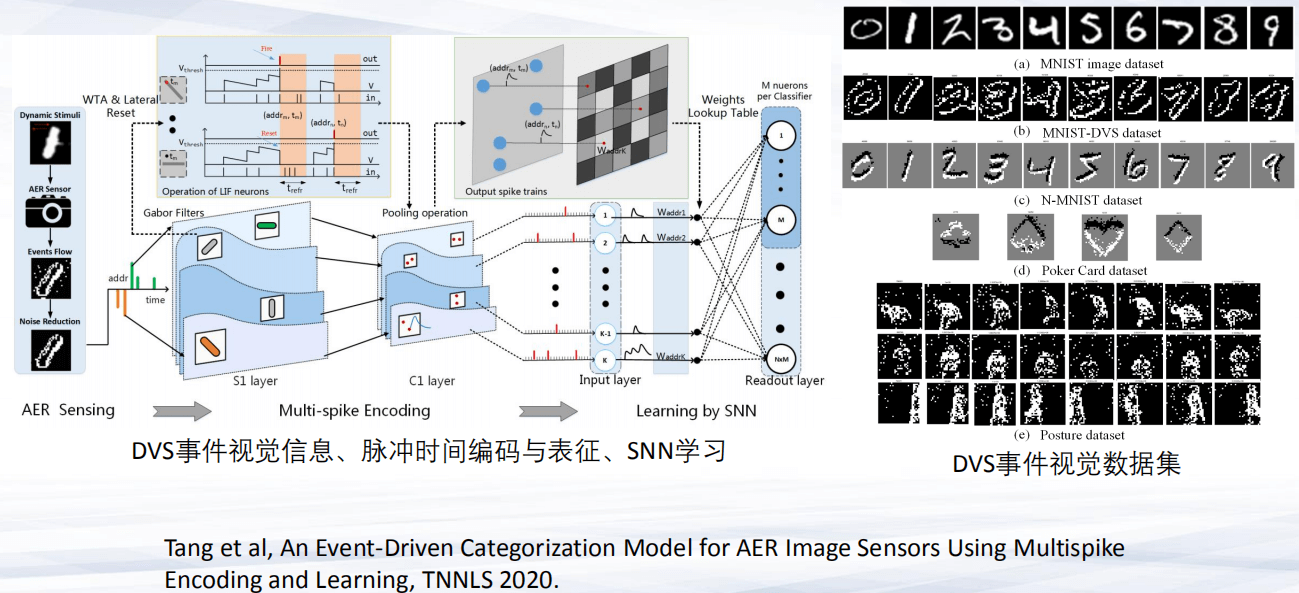
另外,我们在2020年TNNLS的一篇论文中也论述了相关工作:新型的神经形态视觉信息进行脉冲编码和表征来处理动态的视觉信息。
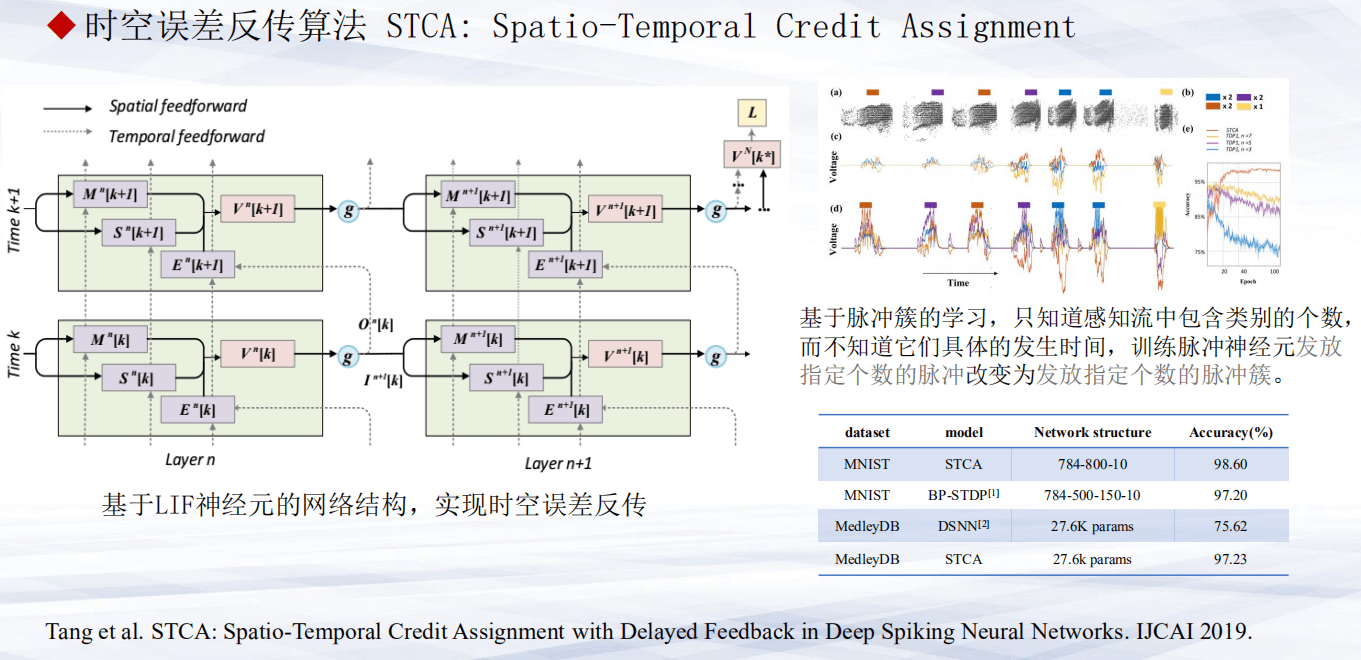
第二,基于深度SNN的信用分配算法。信用分配算法可以高效的解决脉冲神经网络由于时间动力学带来的训练困难问题,不仅在空间上进行误差反传,同时把误差信息传递到脉冲的时间信息上,经过这样的设计我们提出了基于脉冲簇的学习算法,不仅是可以训练神经元在指定时间发放脉冲,而且是指定发放脉冲簇。

第三,脉冲损失函数。如上所示,几种典型的脉冲损失函数,虽然各自具有一些缺陷,但通过改造损失函数,使其能够训练神经元对复杂的时间序列具有响应特性。

如上,左图显示的是杂乱无章的神经元响应,右图是训练后神经元,能够对某些特定信号进行选择性响应。总的来说,做为一个“经过设计“的新型的深层的脉冲网络,其在训练性能上已经超越专门设计和训练的CNN的网络。
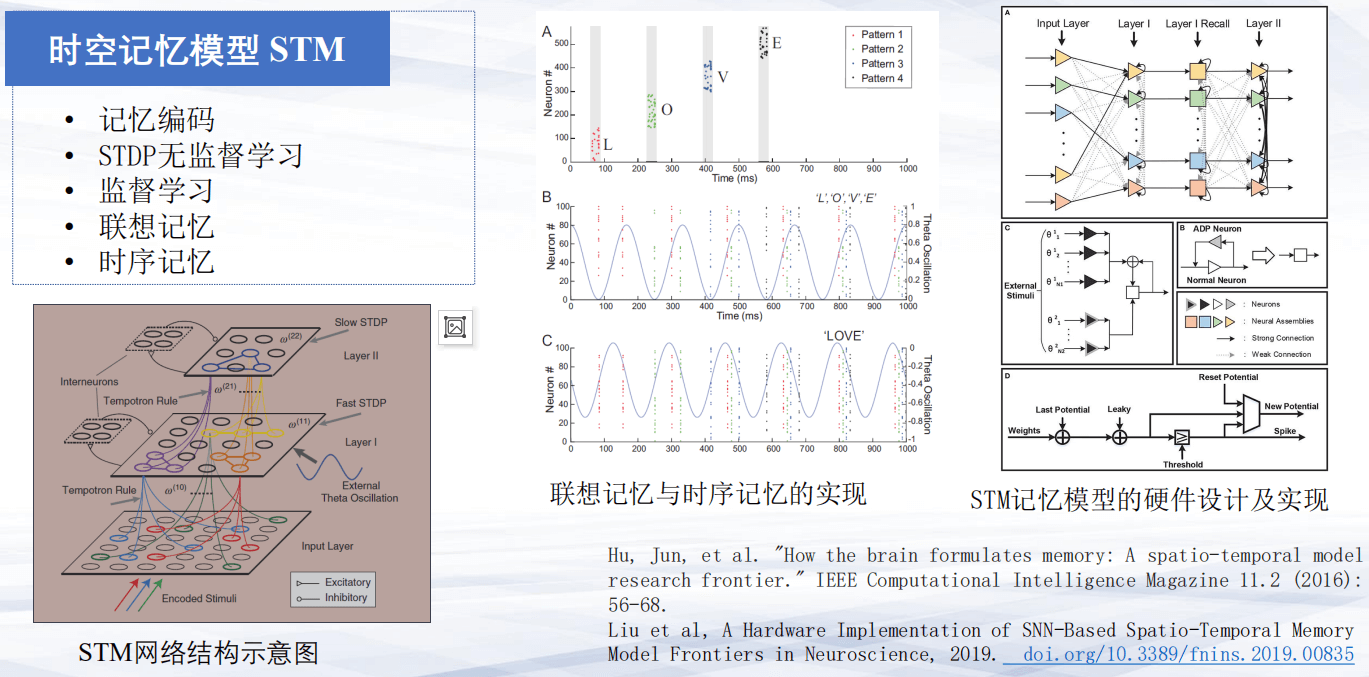
第四,学习与记忆融合。可以通过构建一个能够模仿多层脑区的结构,实现神经元的编码以及监督学习和无监督学习,同时实现联想记忆和时序记忆。具体神经硬件电路图如上右所示:北大黄如院士等人的FPGA硬件的记忆模型的设计和实现。
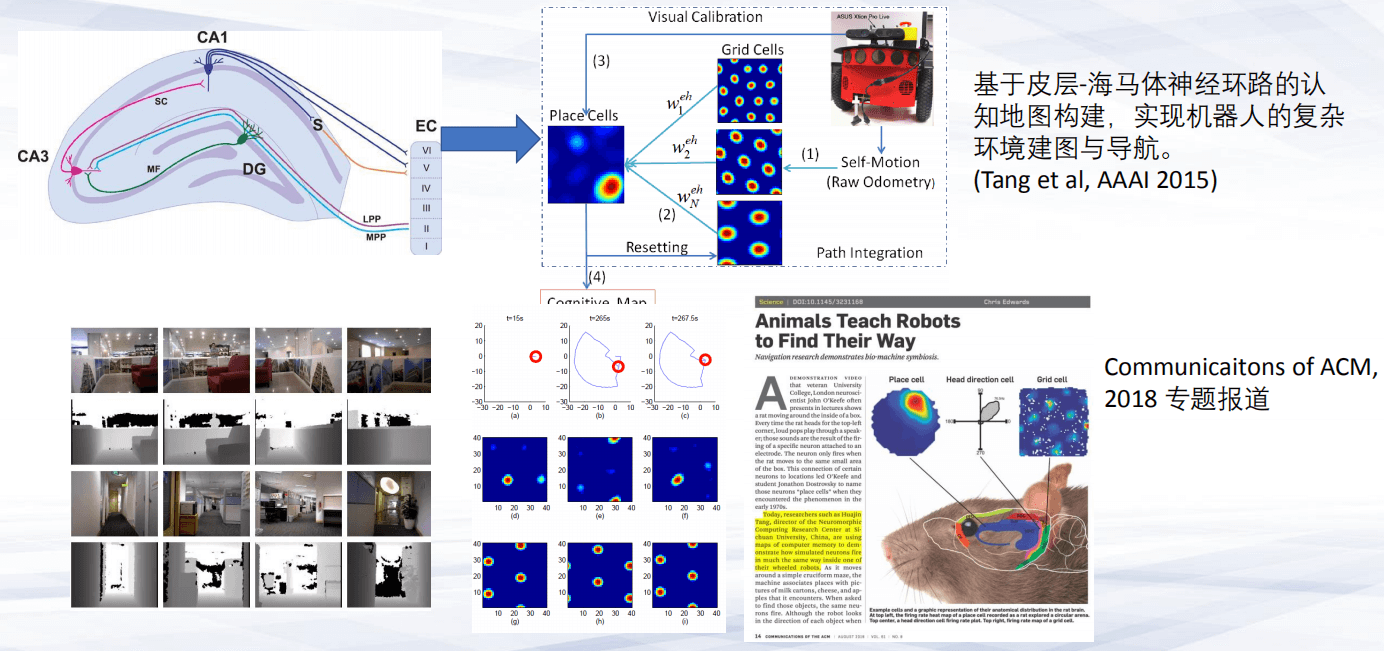
第五,感知-认知-交互闭环设计。目前的初步的成果是把海马体电路“搬到”机器人上,通过硬件模式来实现机器人对空间感知、认知交互的闭环。Communications of ACM 2018专题也介绍了这样的工作,解释了大脑如何帮助机器人对复杂环境空间进行感知,以及依赖空间位置神经元对空间的记忆以及编码的作用。
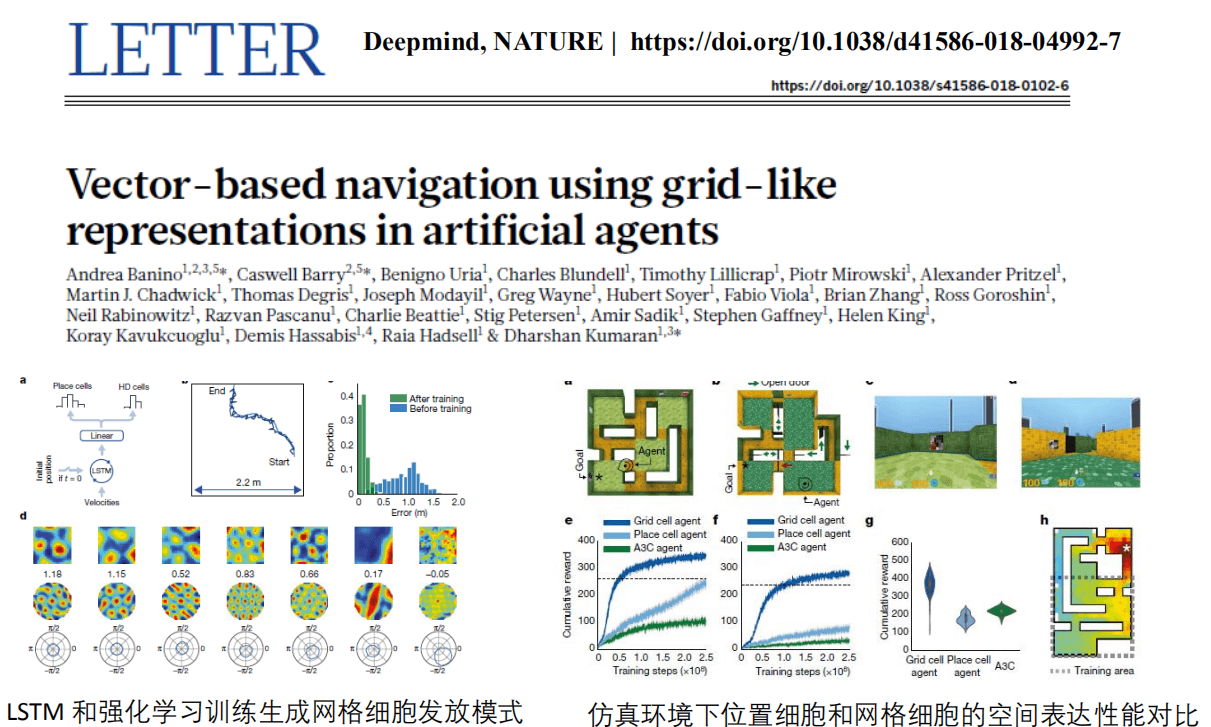
无独有偶,Deepmind也开展了这样类型的工作,但与我们基于模型、大脑结构方式的不同,Deepmind是基于学习和网络来训练神经元,上图(右)展示了他们在虚拟环境下的网络的效果。
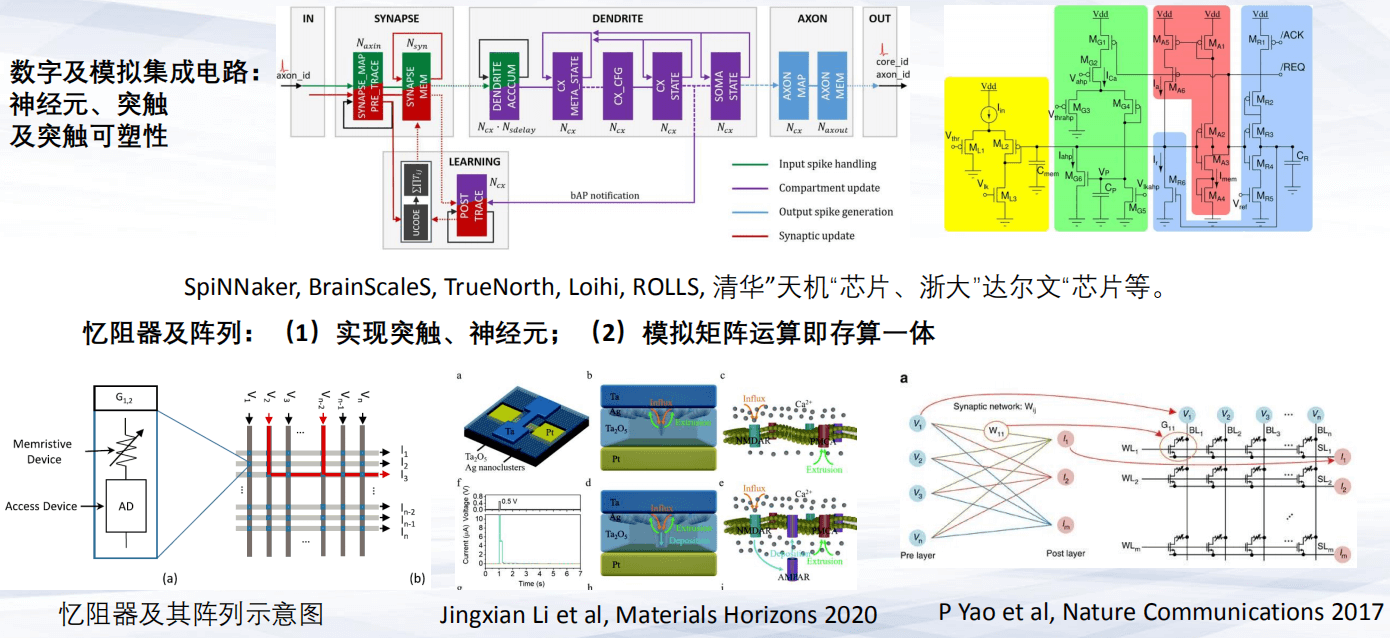
此外,还有在硬件实现上的一些成果。通过数字或者模拟集成电路可以实现神经元、突触以及各种突触可塑性,在这个领域上已经有大量的神经形态芯片的成果,例如SpiNNaker、BrainScaleS、Truenorth、Loihi、ROLLS、清华“天机”芯片、浙大“达尔文”芯片等,都是属于在数字模拟电路上实现架构。另外,未来类脑芯片的潜在突破可能在忆阻器及阵列。利用忆阻器可以分别实现突触和神经元,实现模拟矩阵运算即存算一体。
最后,进行总结与展望。神经形态计算机首先必须具备异构的网络结构,其次包含时序动力学的神经元非线性。还要构建基于多种突触可塑性的信用分配算法:不仅实现模式识别这类成熟的深度学习算法,而且要实现学习-记忆融合的认知计算。未来,我们要把大脑“搬进”机箱让它实现知识的表达、知识的学习、认知以及环境的交互。
《大脑启发的存算一体技术》—吴华强
人物介绍:吴华强 清华大学微纳电子系,长聘教授,副系主任,清华大学微纳加工平台主任,北京市未来芯片技术高精尖创新中心副主任。2000年毕业于清华大学材料科学与工程系和经济管理学院。2005年在美国康奈尔大学电子与计算机工程学院获工学博士学位。随后在美国AMD公司和Spansion公司任高级研究员,从事先进非易失性存储器的架构、器件和工艺研究。2009年,加入清华大学微电子学研究所,研究领域为新型存储器及存算一体技术,先后负责多项自然科学基金、863、973和重点研发计划项目和课题。在Nature, Nature Communications, Proceedings of the IEEE等期刊和国际会议发表论文100余篇,获得美国授权发明专利30余项,获得中国授权发明专利40余项。

我的报告将从硬件的挑战,研究进展以及展望三方面来介绍大脑启发的存算一体技术。
人工智能无处不在,从云端到我们手机端都有很多人工智能。不同的人工智能应用对芯片的需求是不一样的,比如数据中心、汽车无人驾驶要求算力特别高,而智能传感网、物联网和手机希望耗能低,追求高能效。不同应用对芯片的不同需求给了芯片领域很多机会。
AI时代硬件的挑战
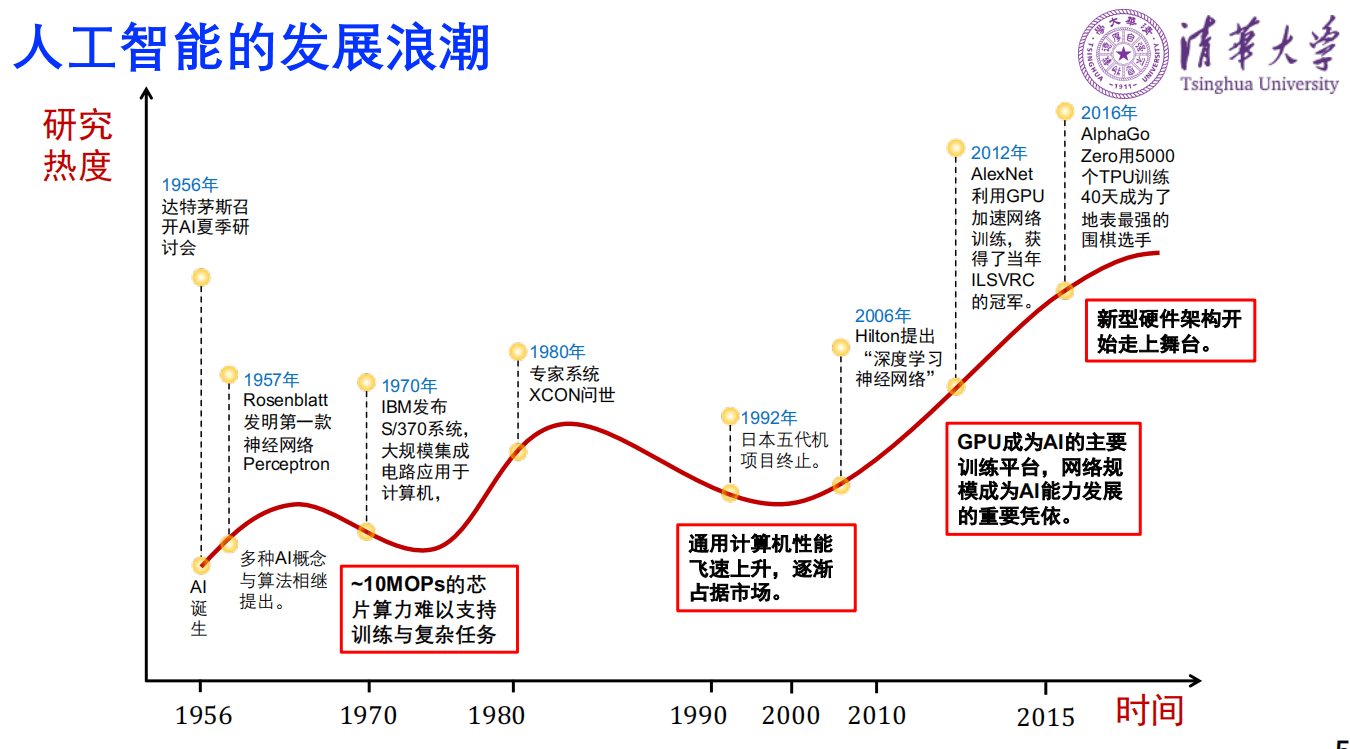
人工智能的三个发展浪潮和硬件算力也有关系。从第一款神经网络Perceptron 网络AI开始火起来,到70年代进入低谷,一个非常重要的因素是,虽然有很好的理论模型,但是没有足够的算力。
后来专家系统出现,第二波浪潮又起来。这时候很多人做专门围绕人工智能的计算机。同时代摩尔定律快速推动芯片的发展,通用计算机的性能飞速上扬,专业计算机能做的通用计算机也能做,因此逐渐占据市场,第二波浪潮又下去。
第三波浪潮,深度神经网络的提出到利用GPU加速网络训练,GPU成为AI的主要训练平台。有了更大的算力,网络规模快速提升。AlphaGo Zero需要5000个TPU训练40天才成为地表最强的围棋选手,花费的时间还是很大的,因此人工智能的广泛应用需要硬件能力革新,支撑人工智能的发展。
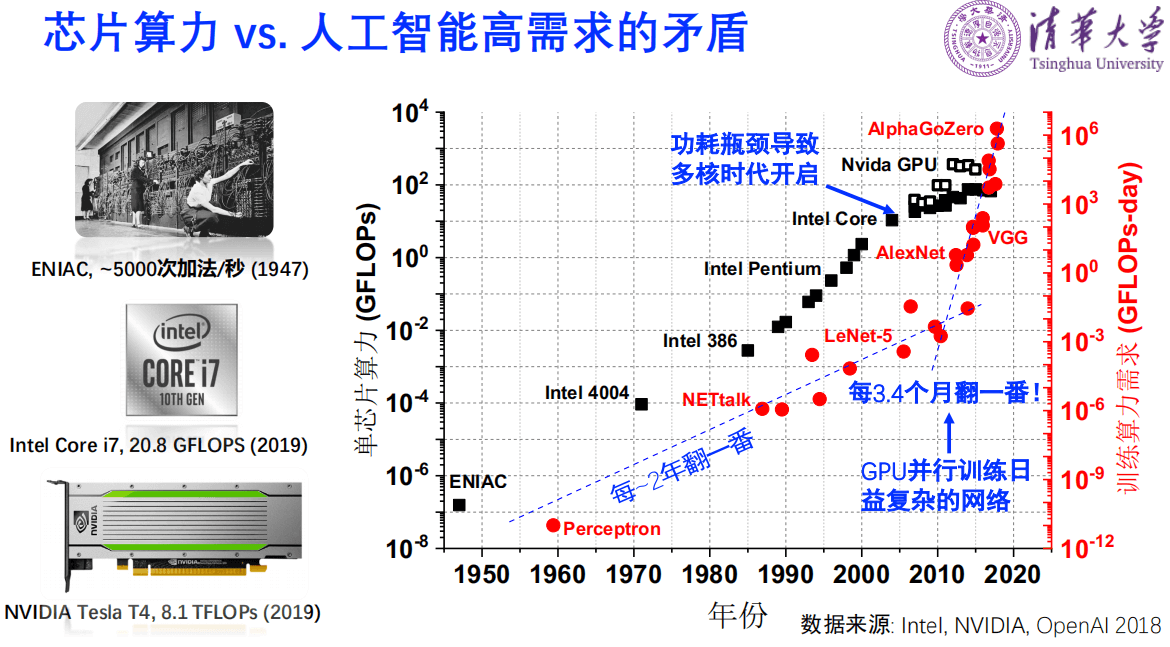
芯片能提供的算力和人工智能的高需求是很矛盾的。第一台计算机ENIAC出现在1947年,算力是每秒钟5000次左右。英特尔2019年的CPU大约是20.8GFLOPS。我们看到它的变化是围绕着摩尔定律,即每18个月翻一番的集成度来提升算力。但是目前AI的需求是每3.4个月翻一番。因此需要寻找新方法提供算力。
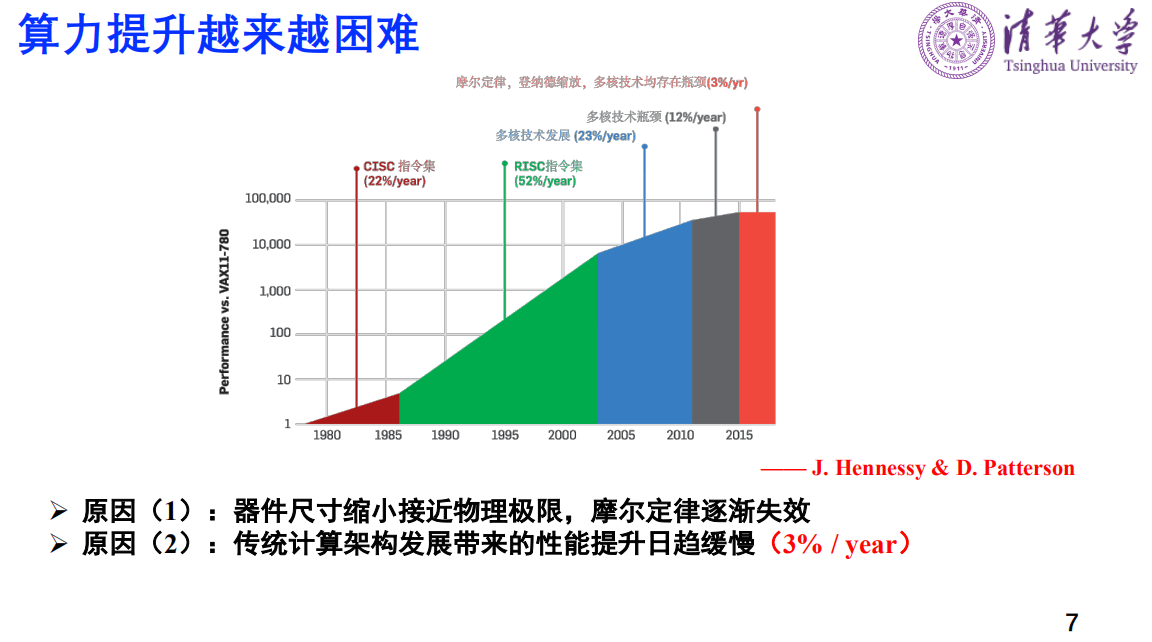
算力提升越来越困难有两个原因,一是过去摩尔定律是把器件做的越来越小,现在器件尺寸缩小已经接近物理极限了,所以摩尔定律逐渐失效。二是传统计算架构发展带来的性能提升日趋缓慢。现代计算系统普遍采用信息存储和运算分离的冯诺依曼架构,其运算性能受到数据存储速度和传输速度的限制。
具体来说,CPU的计算速度小于1纳秒,但是主存DRAM是百纳秒左右,也就是存储的速度远远低于计算速度。在能耗上,以TSMC45纳米的工艺为例,加减乘小于一个pJ,但是32位DRAM的读要高达640个pJ,这一比也是百倍的差距。
因此存储速度远远低于CPU的速度,而存储的功耗也远远高于CPU的功耗。这还没有讲存储的写,写的功耗会更高。这样整个系统的性能受到数据存储速度和传输速度的限制,能耗也因为存储读的功耗和写的功耗很大,导致整个系统功耗都很大。
存算一体技术的研究进展

现在可以看到很多新的计算出来了,量子计算、光计算、类脑计算、存算一体。所以当我们要思考未来的计算时,我自己觉得量子计算、光计算是向物理找答案,类脑计算、存算一体是向生物找答案,也就是向大脑找答案。
著名的人机大战,人工智能选手 AlphaGo用了176个GPU、1202个CPU,功耗是150000W。而我们大脑体积大概1.2L,有1011个神经元,1015个突触,思考的时候功耗是20W。大脑的功耗这么少,这么聪明,这里面还有这么大容量的神经元、突触。所以我们希望用脑启发设计新的人工智能芯片。
我们想通过向生物学家学习、向神经学家学习,来看看大脑是如何处理计算的。大脑有几个特点,一个是有大量的神经元连接性,以及神经元加突触的结构,一个神经元将近连接了1万个突触。第二个它的时空信息的编码方式是用脉冲的方式。我们希望模仿大脑的结构和工作机制,用脉冲编码的形式来输入输出。
生物突触是信息存储也是信息处理的最底层的生物器件。我们想在芯片上做电子突触新器件,做存算一体的架构。新器件方面我们主要研究的是忆阻器,它的特点是可以多比特,同时非易失,即把电去掉以后可以保持这个阻值,并且它速度很快。还有很关键的一点,它和集成电路的CMOS工艺是兼容的,可以做大规模集成。近十年我们一直围绕这个器件来做其优化和计算功能。
美国DARPA的FRANC项目提出用模拟信号处理方式来超越传统的冯·诺依曼计算架构,希望带来计算性能系统的增加。任正非在2019年接受采访时说,未来在边缘计算不是把CPU做到存储器里,就是把存储器做到CPU里,这就改变了冯·诺依曼结构,存储计算合而为一,速度快。阿里2020年的十大科技趋势里提到计算存储一体化,希望通过存算一体的架构,突破AI算力瓶颈。存算一体的理念也是受大脑计算方式启发的。
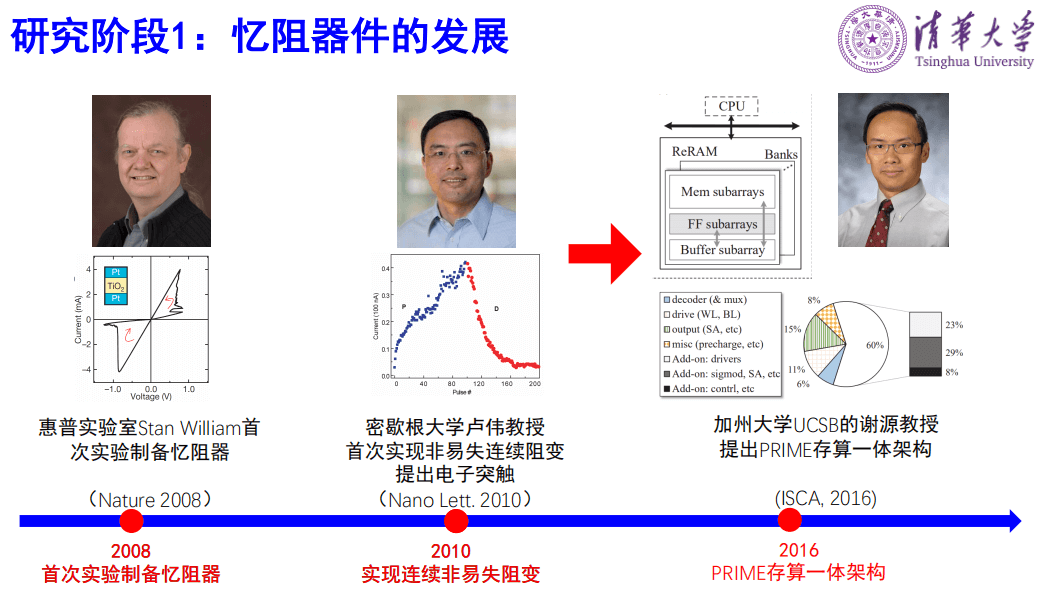
基于忆阻器的存算一体技术可以分为三个阶段:第一个阶段是单个器件的发展阶段。2008年惠普实验室的Stan William教授首次在实验室制备了忆阻器,之后美国密西根大学的卢伟教授提出了电子突触概念,美国UCSB大学的谢源教授提出了基于忆阻器的PRIME存算一体架构,引起广泛关注。
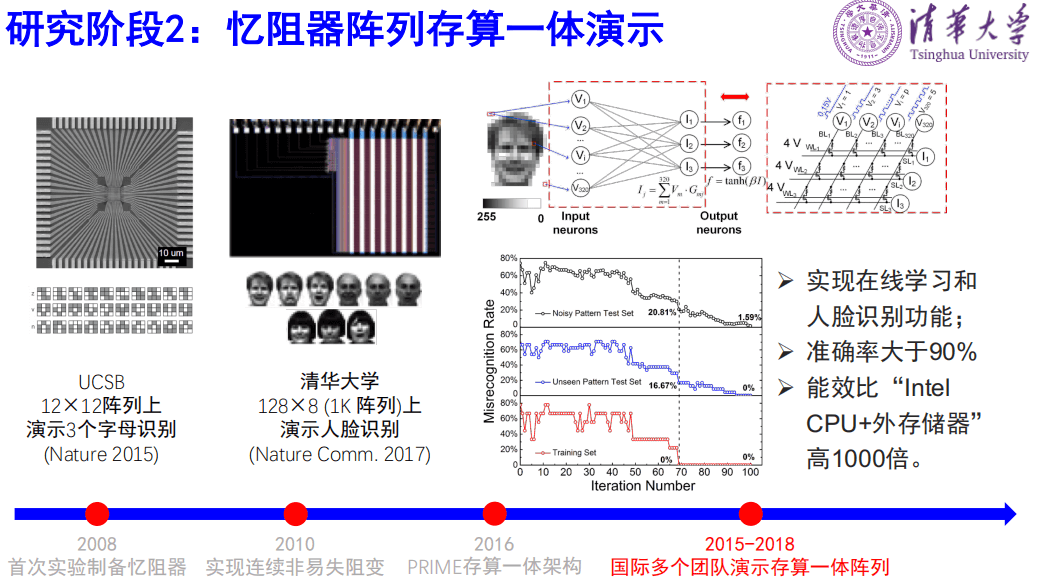
第二个阶段开始做阵列,2015年UCSB在12×12的阵列上演示了三个字母的识别,我们团队2017年在128×8的阵列上演示了三个人脸的识别,准确率能够大于95%,同时期还有IBM,UMass和HP等研究团队实验实现了在阵列上的存算一体。

第三个阶段是存算一体芯片,我们以芯片设计领域的顶会ISSCC上近几年发表的文章为例,2018年松下展示了多层感知机的宏电路,2019年台湾地区新竹清华大学和台积电联合演示了卷积核计算的宏电路,今年清华和斯坦福合作做的限制玻耳兹曼机宏电路。
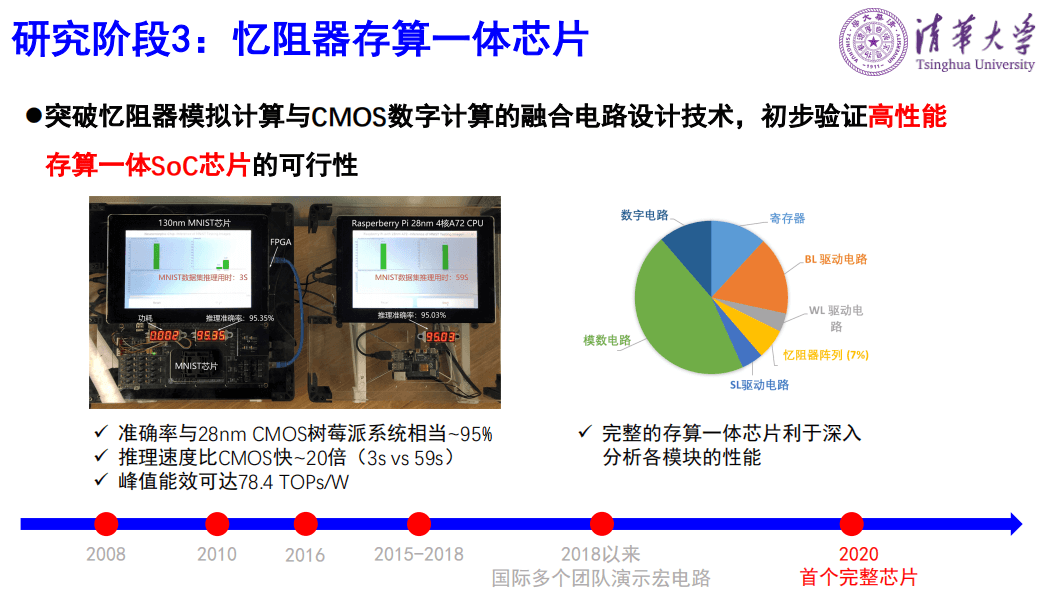
上图是今年我们清华团队完成的一个全系统集成的完整的存算一体芯片,从系统测试结果来看,这个芯片能效高达78.4TOPs/W,是相当高的。我们还做了一个对比,一个是存算一体的芯片和系统,一个是用了树莓派28纳米的CPU。我们的芯片跑完一万张图片是3秒,而他们是59秒,我们的速度要快很多,准确率却相当。
今年1月我们在Nature上发表了一个忆阻器存算一体系统的工作。这个工作主要是把多个阵列放在一起组成一个系统,并验证是否能用作模拟计算来实现AI的工作。我们提出新型混合训练算法,实现了与软件相当的计算精度。还提出了新型卷积空间并行架构,成倍提升了系统处理速度。
为什么忆阻器存算一体适合人工智能呢?因为交叉阵列结构特别适合快速矩阵向量乘法。存算一体可以减少权重搬移带来的功耗和延时,有效地解决目前算力的瓶颈。另外,人工智能更关注系统准确性,而不是每个器件的精度,这特别符合忆阻器和模拟计算的特点。
我们还和毕国强老师合作了一篇综述文章。利用脑启发来设计人工智能芯片,我们把大脑从I/O通道,到突触,神经元,到神经环路,到整个大脑的结构,都和电子器件做了对比。文章题目叫《Bridging Biological and Artificial Neural Networks》,发表在2019年的Advanced Materials上面,如果大家感兴趣可以阅读。
展望未来,希望能够做一个存算一体的计算机系统。以前是晶体管加布尔逻辑加冯·诺依曼架构,现在是模拟型忆阻器加模拟计算和存算一体的非冯架构。
《神经元稀疏发放在视听觉通路上的作用》—胡晓林
人物介绍: 胡晓林 ,清华大学计算机科学与技术系副教授。2007年在香港中文大学获得自动化与辅助工程专业博士学位,然后在清华大学计算机系从事博士后研究,2009年留校任教至今。他的研究领域包括人工神经网络和计算神经科学,主要兴趣包括开发受脑启发的计算模型和揭示大脑处理视听觉信息的机制。在IEEE Transactions on Neural Networks and Learning Systems, IEEE Transactions on Image Processing, IEEE Transactions on Cybernetics, PLoS Computational Biology, Neural Computation, European Journal of Neuroscience, Journal of Neurophysiology, Frontiers in Human Neuroscience, Frontiers in Computational Neuroscience 等国际期刊和CVPR, NIPS, AAAI等国际会议上发表论文80余篇。他目前是IEEE Transactions on Image Processing和Cognitive Neurodynamics的编委,曾担任IEEE Transactions on Neural Networks and Learning Systems的编委。

这次的演讲题目是《神经元稀疏发发放在视听觉通路尚的作用》,主题是神经网络的发展,如何促进神经科学的研究,具体内容是AI(人工智能)到BI(脑智能)两个点(方面)的工作。
用深度学习解析视觉密码
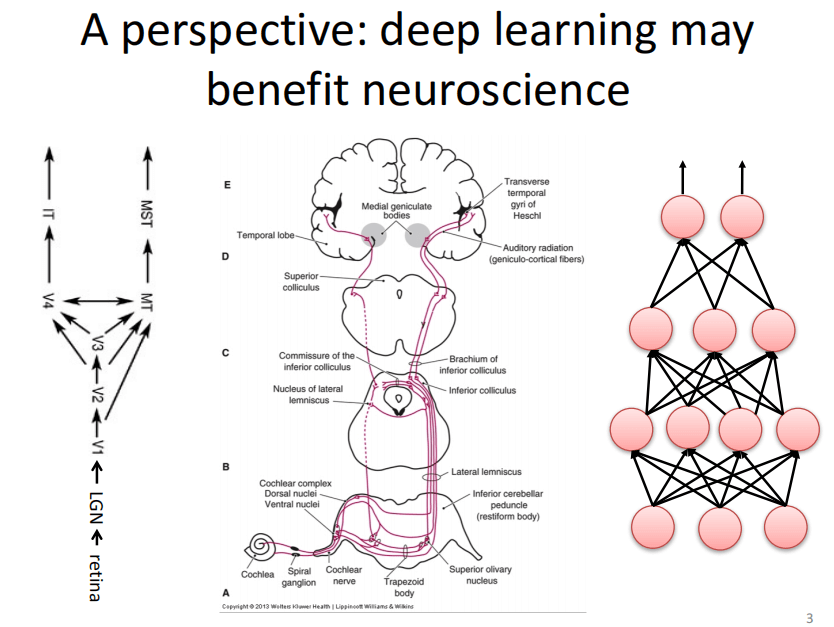
首先看一下背景。如上图所示,左边是视觉系统大致的通路,信息从视网膜到LGN的大细胞层到脑皮层;中间是听觉皮层,信息从耳蜗一直传到听觉皮层;右边是典型的人工神经网络。以上三三种属于层次化的结构。
因此,神经网络和视觉、听觉系统有一定的相似性,毕竟,至少是层次化的结构。那么,基于这种相似性,能否利用现在神经网络的飞速发展,从而促进对大脑的视觉、听觉或者其他感觉皮层工作机制的理解?
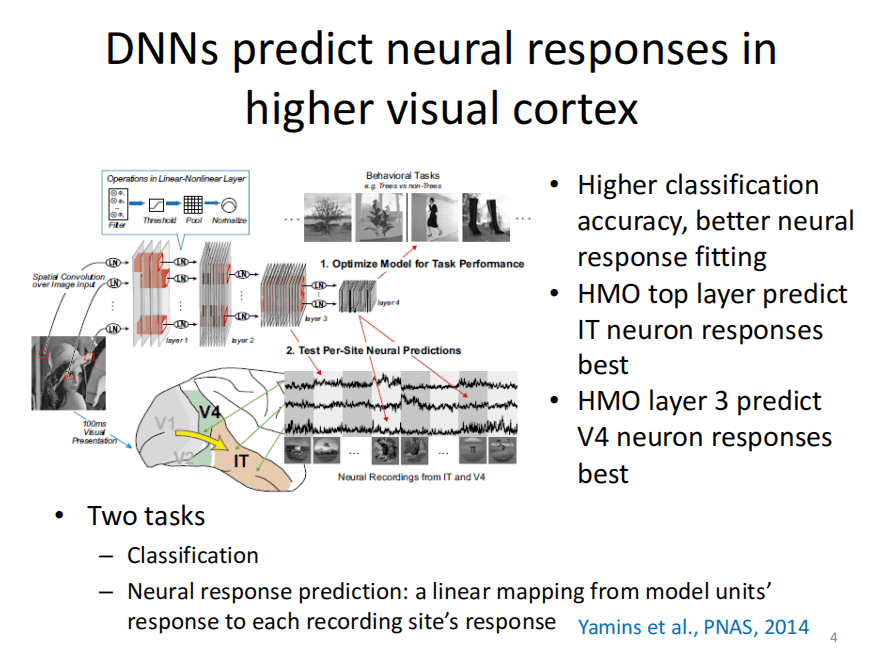
在2014年,MIT的教授Yamins等人进行了相关工作,他们用CNN(卷积神经网络)训练一个图片分类模型,然后把给CNN”看“的图片拿给猴子看;然后记录猴子不同视觉区域的神经元的发放,例如V4和IT两个区域;最后去比较神经网络不同层和猴子的不同大脑皮层(例如V4和IT两个区域)神经元的相关性。发现不同神经网络层的神经元反应的特点正好对应猴子IT、V4区域反应的特点。这是第一次证明神经网络和大脑视觉皮层有关联。
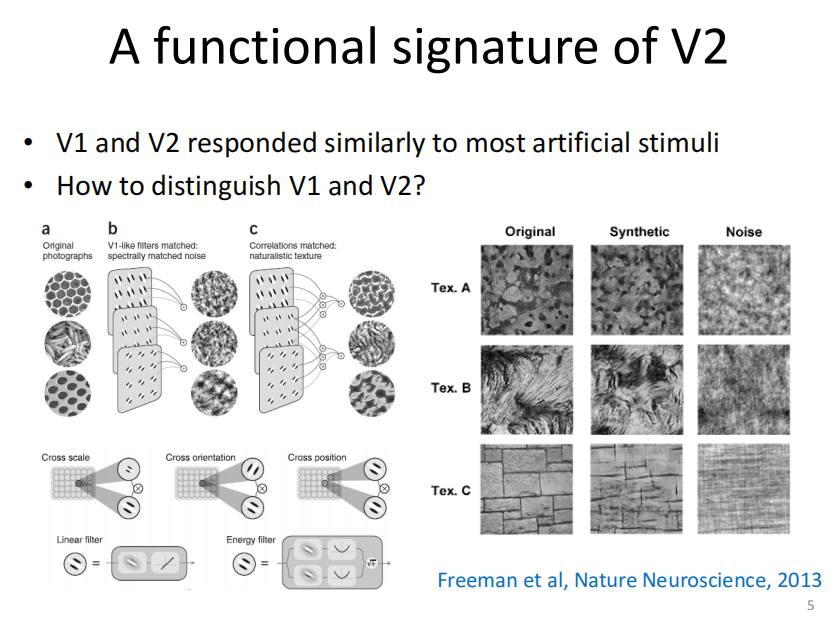
2013年纽约大学进行了一个实验,具体操作是让猴子和人去看两种不同的图片,第一种是合成的自然风景图片(这类图片与自然图片含有类似的复杂的统计特性),第二种是噪声图片(这类图片与自然图片含有类似的能量谱)。
图注:NT代表是自然图片(第一类),SN代表噪音图片(第二类)。
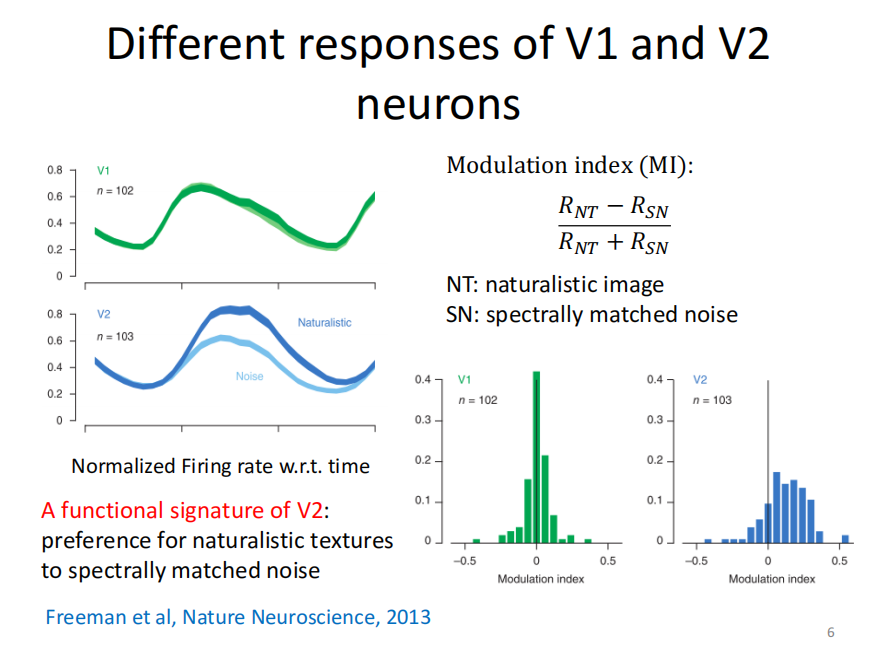
然后给猴子这两类图片,发现V1的神经元对这两类图片的反应相似;V2神经元对于NT一类的图片反应比较高,对于SN类的图片反应比较低。
另外,研究员还定义了Modulation Index,用来判断神经元“喜爱”哪类图片(值越大越喜爱第一类图片)。实验结果表明,在V1区域,所有的神经元的Modulation Index都集中在0附近。在V2,大部分神经元的Modulation Index都是正的,这意味着大部分的神经元都喜爱第一类(像自然)图片。
随后,在2015年,日本的一个研究小组通过研究猴子的V4区域,发现了同样的结论。即V4的神经元和V1相比较,V4更喜欢具有高阶统计特性、像自然图像的图片,而不是噪声。
那么,为什么V2和V4的神经元喜欢像自然图片的图片,而不是噪声图片?这个问题有两种研究方式,一种是用传统的计算模型,另一种是深度学习模型。但是对于第一种来说,计算神经科学领域早期的模型都是单层,又因为视觉皮层是层次化的结构,所以只有满足层次化结构的深度学习符合要求。
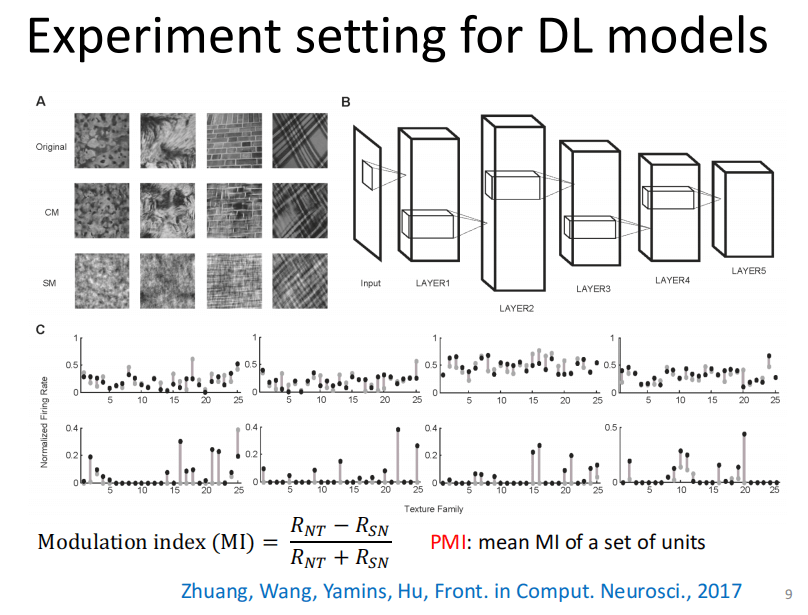
于是,我们构建了一个标准的深度学习模型,然后用同样的方式从自然图片中创造出两类图片(两类图片和上述类似,即一种自然,一种噪音)。把这两类图片输入到模型里之后,记录每一层神经元的反应。随后,定义每个神经元的Modulation Index,同样,Modulation Index的值越大,说明神经元越喜欢具有高阶统计特性的图片。
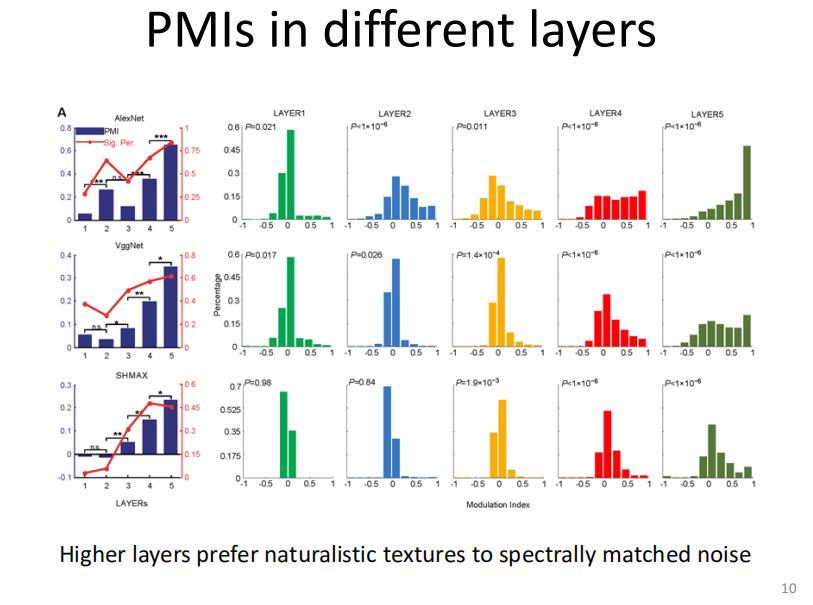
结果有三行,第一行是AlexNet,第二行是VggNet,第三行是SHMAX。AlexNet本身有五个卷积层,Vgg以max pooling层为界把相邻的几个卷积层分成一个大层,所以也有五个层。统计每个大层的Modulation Index(上图中蓝色的柱状图)之后,发现随着层数增高,Modulation Index的值越大,因此在第五层的大部分神经元更加喜欢第一类图片。
SHMAX的结构跟上面两个网络的结构基本是一样的,唯一区别是它的学习是一种逐层无监督学习,但也可以得到一样的结论。
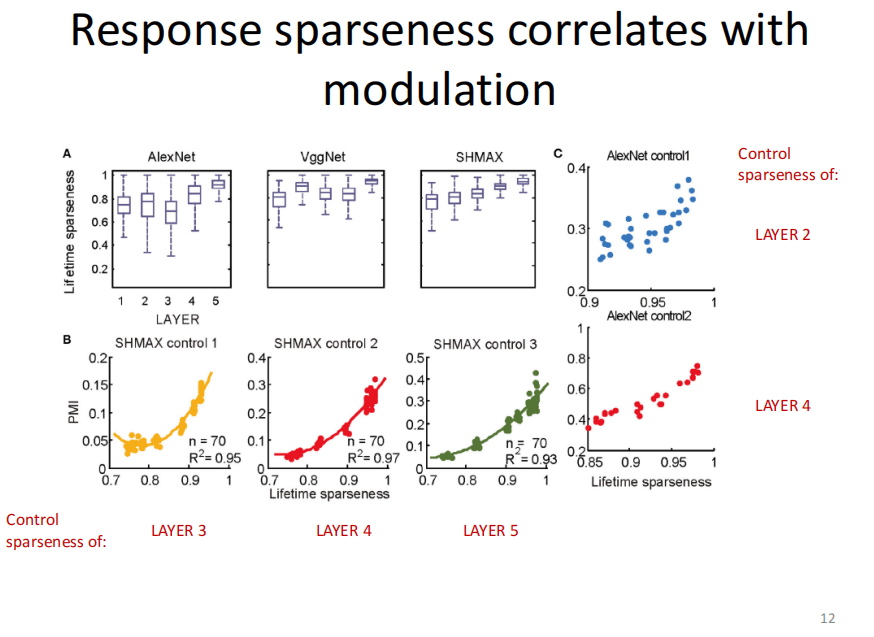
因此可以得出结论:对于有监督学习模型和无监督学习模型,它们的Modulation Index都是随着层数的增加而增大。
那么,为什么这些神经网络具有这样的特性?在考察众多因素之后,发现Response Sparseness非常重要,它和Modulation Index成正相关的关系。Sparseness是指看过很多图片后,有多大比例的神经元是不发放的。无论是AlexNet、VggNet还是SHMAX,都有一个ReLU,决定了有些时候神经元是不发放的,有些时候是发放的。
随着层数上升,Sparseness会越来越强,这和Modulation Index的趋势类似。具体实验表明,AlexNet、SHMAX每一层的稀疏性越高,Modulation Index也会越高。
总结一下,通过上述工作,我们在三个深度学习模型上发现和猴子视觉皮层高层反应特点类似的一个结论。
用深度学习探索听觉密码
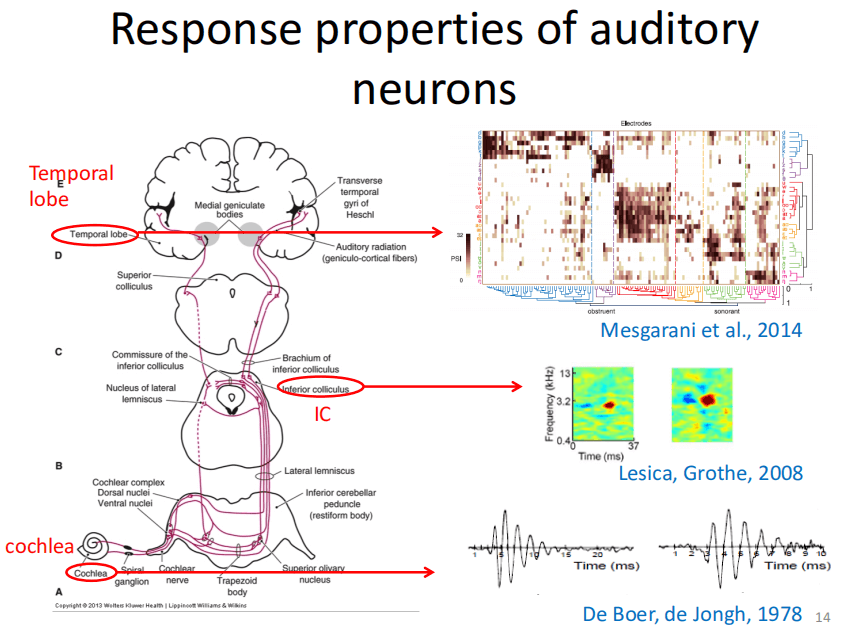
下面介绍关于听觉的工作。刚才已经提到听觉皮层也是层次化的结构,人们在听觉通路上也发现了很多结论,例如在耳蜗后有一个听觉神经纤维,进行刺激后,其反应呈小波的形式。在下丘,神经元的感受可以测出来的,并用时频图表示。在听觉皮层,有很多神经元可以特异性地偏爱一些音素。
注:“ba”里面有辅音“b”和元音“a”,这些元音辅音又叫音素。

如何解释这些结果?计算机科学已经用Sparse coding解释了耳蜗和下丘两个区的神经元的反应情况。具体而言,如上图所示,在Sparse coding模型中,X是输入、S是Response,如果输是语音,最后解出来A(A是每个神经元的感受野),形状类似于小波。
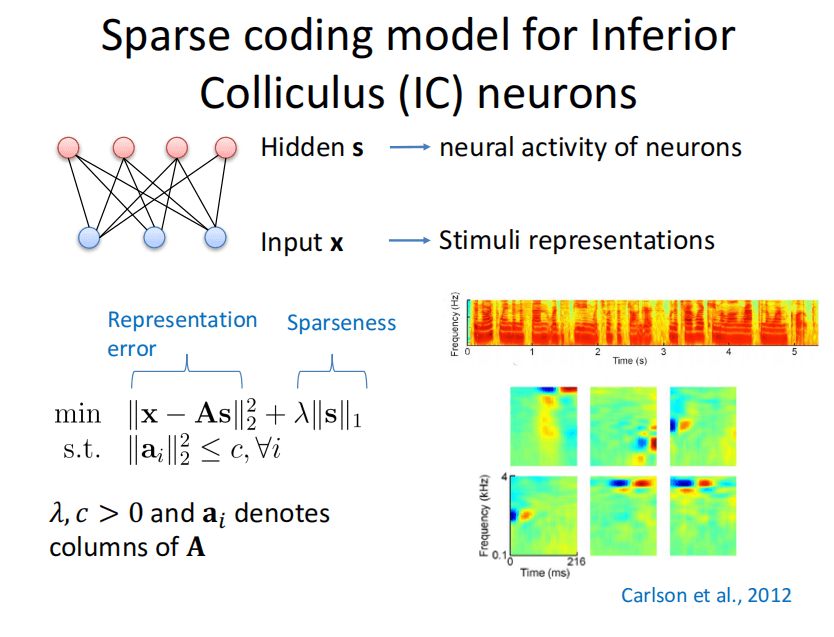
在IC区(inferior colliculus),采用同样的模型,用频谱图作为输入,然后求解Sparse coding模型,然后得到神经元的感受形式如上图所示。
前面两层级的神经元反应特点已经被解释了,第三层级(最高层)的这个现象怎么解释呢?在给做手术的病人插电极实验中发现,有些电极特别喜欢辅音(d、g、e、h、k、t),有些电极喜欢摩擦音,还有的喜欢元音(o、e、i)。也就是说人类神经元对音素有特异化的表达,这种表达是怎么出现的呢?还有一个问题是,比较低的皮层能用Sparse coding解释他们的现象,那Sparse coding模型能不能解释高层的现象呢?

为了回答这两个问题,我们构建了层次化的稀疏编码模型,即典型的CNN结构。不同之处在于,每一层的学习不再用BP算法,而是用Sparse coding,第一层学习完以后再学习第二层,第二层学完以后再学第三层,从底层到高层依序学习。值得一提的是,其输入就是时频格式的信号。
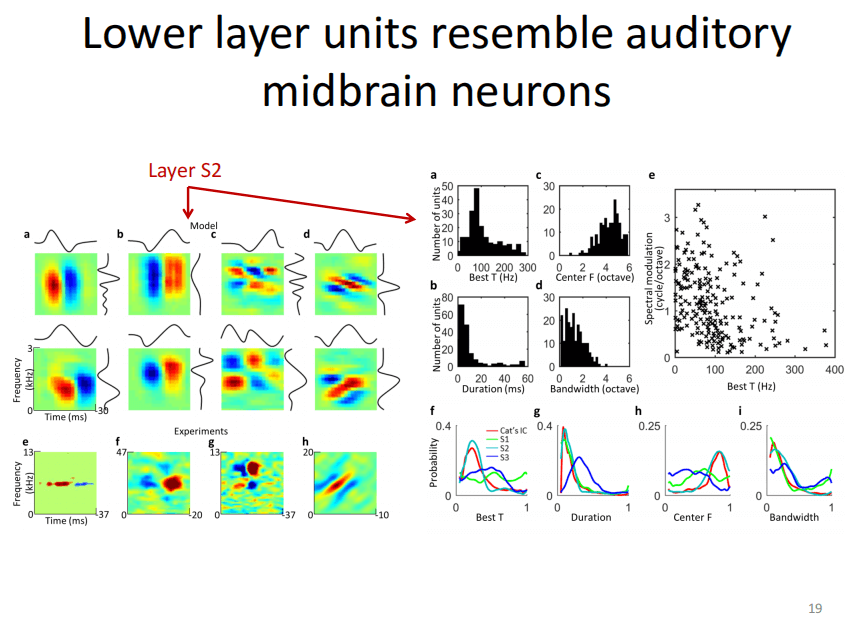
除了中间层,我们还发现顶层(第六个max pooling 层)很多神经元特异性的喜欢一类音素(B、P、L、G),还有一些神经元喜欢元音(a、o、e),而且聚集效应在顶层最明显。
虽然这些特征,在下层也存在,但效应相应低一些。换句话说,此模式并不是陡然在顶层出现,在下面的层级早已显现,只不过神经科学家们没有测到下面区域神经元的表达。

最后,总结一下,我们发现一些深度学习的模型在中层和高层的神经元的反应,和视觉、听觉的中、高层的真实的神经元的反应有一致性。另外,我们并没有尝试拟合生理学的数据,但是就是出现了这样的特性。
第二个结论,稀疏编码。前面研究的这些深度学习模型都有一个稀疏发放的特点,而且稀疏发放的特点和神经科学的发现有重要的关系。当然用深度神经网络研究神经科学的问题存在巨大的缺陷,毕竟,人工模型的细节结构和生物上的系统存在着非常大的差异,所以无法用“粗糙“的学习模型研究神经科学的问题。
▍ 跨学科讨论
除了主题报告,未来论坛还邀请了嘉宾进行主题讨论,除了唐华锦、吴华强、胡晓琳之外,还有来自北京师范大学认知神经科学与学习国家重点实验室的毕彦超,来自中国科学技术大学神经生物学与生物物理学系毕国强,来自北京大学信息科学技术学院长聘教授吴思等人参与了讨论。以下是讨论议题:

第一:脑科学已经为AI发展提供了什么思想、方法和技术?有哪些典型案例?
吴华强:举一个例子:树突计算的工作。过去神经网络里只有神经元和突触,树突在神经网络里面不体现。即所有的突触的信号都传到胞体上和neuro上,然后Neuro再进行聚合。
另外,最近研究发现,区别于突触,一些忆阻器和树突有类似的功能,可以进行积分和过滤功能。所以,在人工智能中引入树突,会不会让整个计算更加准确?于是我们进行了实验,将突触和树突以及胞体连在一起,设计了一个小的识别系统,实验结果表明,在识别街边的数字,门牌号时,其准确率大幅度提高了,动态能效也提高了30倍。所以,借助脑科学确实能够提升AI网络的效率。
山世光:猜测树突是否有滤波功能,让我联想到了MCP的神经元模型(莫克罗-彼特氏神经模型),其里面是一个积分,那么您的工作是不是相当于对每一路的输入又添加了一层滤波?
吴华强:器件可以对它进行过滤,我介绍的那个器件并不是百分之百把树突功能都模仿了,而是受其启发。另外,去年10月,我访问MIT,有个教授关于树突计算的报告非常有意思,结论是:树突的长度和智慧是有关联。这也会给AI带来很多参考。
毕国强:吴老师讲的树突计算非常有价值,但什么因素会导致效能提升呢?树突的滤波性质或树突本身的构架?一般人工神经网络构架中每个突触的基本性质是一样的,树突构架可能引入了异质性。另外,树突结构本身的层级结构的复杂性也可能会对最终产生的计算能力有一些影响。关于异质性,STDP应用到人工神经网络效果不佳,可能的原因就是异质性。因此,吴老师树突结构的研究工作,有助于观察到底哪些特征产生了性能的提升或者改变。
从哲学层次考虑,生物的大脑和神经系统是很多年进化的结果,其经过了自然选择,当然接近最优的结构。但,其在多个尺度上具有复杂性,例如在最小尺度上,突触这类不到一微米大小的“设备”也非常复杂,更不用说环路和整个大脑的结构了。
因此,我们模仿大脑,会在不同尺度、不同层次上获得不同的启发。在这过程中需要明确的是:哪些特性、特征能够对AI起到正面的作用。短时间内无法实现全面模仿大脑,短时间内要全面地模仿大脑肯定是不现实的,所以我们需要从复杂的层级结构中抽出关键特性一步一步模仿。
胡晓林:AI的有很多工作其实是从脑科学启发过来,追根溯源到1943年,麦克和皮茨这两个人第一次提出人工神经元—MP神经元,如果没有他们提出人工神经元,后面的CNN会不复存在。当时,这两人研究神经科学,基于尝试发明计算模型并解释大脑工作的目的,提出了逻辑运算的MP神经元。
后来Rosenbaltt把MP神经元进行了扩展,得到了多层感知机。再后来,时间到了1989年、1990年,当时YanLeCun等人提出来CNN,其实是受了Neocognitron模型的启发。值得一提的是,Neocognitron是日本人Fukushima提出来的,其结构和现在CNN的结构一模一样,唯一区别是学习方法不一样,毕竟,Neocognitron在1980年提出来时还没有BP算法。
那么,Neocognitron怎么来的呢?它是受到一个神经科学发现的启发,即在猫的视觉皮层有简单细胞、复杂细胞两种细胞,从这两种细胞的特点出发构建了Neocognitron,并尝试去解释大脑怎么识别物体的。
MP神经元和Neocognitron这是两个具有里程碑意义的方法,也是典型的神经科学在AI层面给予我们启发的工作,甚至可以说是颠覆性的工作。
实际上,这次人工智能的腾飞期间,我并没有看到特别多令人非常兴奋的脑启发的工作,虽然也有,但并没有刚才提到的那两个模型的意义那么大。希望这个领域能出现一些新的脑启发的方法,哪怕它们现在的性能非常差,但是十几年、几十年以后,它们也许会成为奠基性的工作。
毕彦超:戈登摩尔曾经说过,了解任何一个智能系统,要从三个层次看:计算、算法和实现。刚才大家讲的“借鉴”大多都在实现(Implementation)层面的。而在计算和算法的层面,也有很多可以参考的地方。
但我目前没有看到这方面的界线,因此认知神经科学或者认知心理学是一个宝藏。才吴老师也提到,在视觉加工的时候,至少人脑和猴脑的视觉绝对不仅仅是识别。它是为了生物的生存、繁衍、规避、社交等等。
另外,对于人来说,并不是特定的单一目标,而对现在的AI计算来说,很多是特定的目标。举例而言—知识存储。在AI层面,其知识存储全都从文本来,但实际上神经科学,知识存储,更主流的观点是从感知经验来、从视觉来、从听觉来、从互动来。
在研究AI的时候,大家经常会问,常识性的知识怎么表达,这一直是个很大的挑战。其实,人脑在神经科学的研究有这方面的答案。
关于“借鉴”,当前在实现层面,已经有很多令人激动的成果,接下来,我希望有更多的宝藏被发掘。
第二:AI在哪些方面已经助力了脑科学的发展?有哪些典型的案例?
吴思:在于我们如何定义AI。如果仅仅是信息理论、动力学系统分析、统计学习等,那么这些都是计算神经科学每天在用的工具,它们一直在助力脑科学的发展。如果一定要强调最新的,比如说深度学习,那么如何将AI用于脑科学是目前的一个研究热点。国际上有多个研究小组,都把视觉系统当成一个深度学习网络,然后训练深度学习网络,同时加入一些生物学的约束,然后用对比的方法观察这个系统能学习到什么,进而回答生物视觉认知的问题。
山世光:我们看到一些工作也都是在验证,深度网络和人的大脑之间似乎在层上有一定的对应性。
唐华锦:我补充一下吴思老师的观点。传统AI提供了很重要的大数据分析工具,尤其是在高通量的脑成像方面,建立了非常精细的脑模型。在实时的脑活动的分析上,比如斑马鱼的活动,如何同时实时记录以及把这些神经元的活动匹配到其他神经元上,也有大量AI深度学习的帮助。包括三维重建,包括树突、轴突之间连接的结构,AI也会起到非常重要的作用。
胡晓林:现在国际上有一个热点,用深度学习的方式去研究深度模型能不能出现以前在生物学实验当中的结果。但这只是第一步,首先要观察深度学习模型是不是具有这样的特点。如果具有这样的特点,
那么能进行什么样的研究呢?
深度学习模型是人类自己构造的,所以此模型中所有神经元都可以测,并不会像生物体那样会受到实验条件限制,导致有些地方测不到。如果有了一个等价模型,在等价的人工智能模型上做一些实验和解释,做一些原理性的探索,会比在动物那种“黑箱”上做更容易一些。
MIT的DiCarlo研究小组对这个问题有一个更进一步的工作。在猴子的高级皮层,神经科学家很难用一个刺激让这些神经元能够以一个很大的发放率去发放。所以,实验进行到越高层,难度越大。
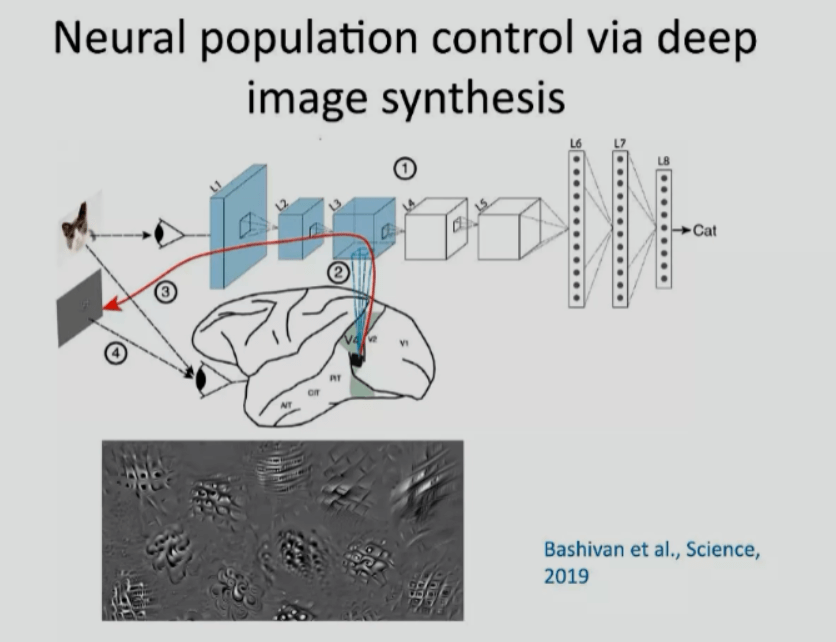
为解决这个问题,他们先构造了一个CNN神经网络,然后把中间的L3层取出来,和猴子V4区域的神经元反应做简单的映射,学出这个映射之后,用猫的照片进行视觉刺激,然后通过人工神经网络的L1、L2、L3,传到V4脑区构成通路,构成真正的生物系统中猫照片通过V1、V2、V3最后传到V4的生物通路的替代模型。
然后他们通过神经网络BP算法反求“刺激”,使得V4区的神经元反应最大。然后再把这些刺激给猴子看,发现V4区的神经元反映远远超出以前用任何刺激所带来的发放率,也就是说如果不用他们这种反求的方式进行刺激,用自然数据是很难让神经元发放这么强烈。于是,此种方法就解决了他们做生理学实验的痛点。
之前和听觉研究的老师有过沟通,他们在猴子的听觉皮层发现大部分神经元都是不反应的,很多人想不通为什么这样,个人认为可能是没有找到合适的刺激。
毕彦超:用AI来理解大脑的,虽然效果很好,但并不意味着真实大脑的模样。例如DNN很多时候能在一定程度上模拟的大脑,并不等于真实神经就是这样的。所以我会特别强地要求去多找一些不同的模型进行对比,才能更好地评估大脑,才有可能为理解添更多的证据。
山世光:现在深度学习的模型是一个黑箱,在过去三年里AI领域已经把可解释AI的研究问题突出来了,很多人做了非常漂亮的工作解释黑盒子模型,接下来的时间里肯定会有更多的发展。
毕国强:从基本的大数据分析到更高层次的模拟,AI在脑科学研究中起到了很多助力作用。人工神经网络在对大脑进行模拟时,只是模拟神经系统的最基本的性质,比如神经元和突触连接。。用简单的性质模拟大脑,能够得到的一些和大脑里面发生的类似的现象,这也反映了非常根本的机制。但是很多事情是没有办法用目前的人工神经网络进行解释,需要进一步的模拟,或者叫计算神经科学的模拟。
AI和计算神经科学没有本质上的严格边界,这种更深层次模型通过加入更多的脑神经系统的特性,就可能模拟神经系统更多的行为,然后再反过来观察哪些性质是哪些行为必须的。当然归根结底,这是一个大脑理解大脑的复杂性问题。
山世光:深度学习和大脑这两个黑盒子如何互相对比?能不能把这个黑盒子打开?我个人理解这有点像鸡和蛋,是可以互动的,即这边进步一点,那边也跟着进步一点。
第三:脑科学研究需要什么样的AI技术来解决什么样的前沿脑科学问题?
吴华强:我们可以用人的大脑研究老鼠的大脑,因此可以先从简单的东西开始研究,我们不能打开自己的大脑,那么就打开“别人”的大脑。
吴思:我特别期望望神经形态研究的发展。我们研究脑科学,提出了各种模型和机制后,如果有一个类脑的硬件系统进行验证。那么,就能更好证明机制和模型是否生物学合理,能否在AI中得到应用。
第四:如何培养更多AI+脑科学交叉研究的人才?
毕国强:目前整个领域,尤其是在国内发展的真正瓶颈,就是怎么样培养更多的交叉学科的优秀人才。
这是一个很大的挑战,因为真正的AI+脑科学交叉学科人才需要对两个学科都要有充分的把握,而这两个学科都是很难的学科,与计算机和应用数学,或者生物学和化学不同,它们中间重叠的部分并不多。
如果想把AI和脑科学连在一起,需要几乎双倍的专业知识。国外有很多值得借鉴的经验,但最关键是需要鼓励青年人追求自己的兴趣,如果感觉大脑很神奇或者AI很神奇,真的想研究它们,理解它们,那就花别人双倍的力气把这两个学科都学好。
另一方面,国内很多课程设置有专业限制,不同专业间的壁垒非常大。在生物系和计算机系这两个学科的要求差别非常大,这时候需要设计真正的交叉学科的课程体系,中国科学技术大学在这方面做过一些努力,例如温泉老师教物理系学生计算神经科学的课程,深圳在建的中科院深圳理工大学也希望建立AI+脑科学的智能交叉学科专业方向,从而建成培养交叉学科顶尖人才的机制。
毕彦超:跨学科有很多特别不容易沟通的地方,虽然用同样的词,其实大家还是固守一些成见,按照自己学科的思路去理解。脑科学很多是科学的思维,AI很多是工程思维,在沟通过程中会碰到一些壁垒,这时候怎么更开放思路,思考背后大家真正关心的大问题,而不是当前具体某个名词或者小问题的完全对应,特别的重要。
山世光:心理所设计本科专业的课程体系里有人工智能相关课程,其实需要考虑很多因素,例如课程谁来讲、讲什么、学生之前有没有接触过编程课等等,确实课程体系建设方面有非常多的地方需要努力。
唐华锦:浙江大学新招的人工智能专业本科生,其专业设置了AI+脑科学的交叉课程,在推动培养新一代的AI+脑科学方面的交叉人才上已经在布局,相信清华、北大也有类似课程的设计。
胡晓林:没有编程基础,开设人工智能课程确实很难。我觉得反过来,如果在信息科学院系开设脑科学是否相对比较容易?因为学神经科学可能不需要特别系统的,像数学、编程那样要经过好几年的培养。
一、大脑如何完成学习-记忆融合的?
唐华锦:这涉及对记忆的理解问题。记忆通过神经元的群组编码实现。比如对某个概念,必须有一组神经元对概念进行表述,这组神经元就要学习概念进行响应,从而加强这组神经元之间的连接。
如果此概念和另一个概念之间存在联想关系,那么不同的神经元群组间要形成一个新连接,而这个连接可以把不同概念联系起来。因此群组内的神经元连接以及群组间的神经元连接都要通过学习的方式实现,要么通过无监督STDP学习规则,要么通过有监督的方式,从而实现学习和记忆的融合。
二、现在的MCP模型是没有记忆力,那么以一个神经元为例,它如何做到“学”和“记”一体?
吴华强:突触会通过学习不断变化,电子突触器件也是一样。例如现在存的值是10欧姆,经过学习把它变成12欧姆或者9欧姆,通过变化就实现了记忆。
一个芯片要做的比较智能的话,集成度非常关键。例如在10个突触的情况下,每个的变化、参数离散性都会大幅度影响系统准确率,但如果芯片集成10亿个器件,那其实单个器件就不会有太大影响。这要和数学理论家进行合作,需要在理论上证明器件的离散和整个网络的准确率的关系。
山世光:忆阻器交叉阵列相乘后,电流需要ADC转换吗?如果转换的话,ADC是否会占用大量时间?现在激活函数是靠软件实现还是已经有硬件实现?
吴华强:忆阻器阵列可进行乘加运算,电流需要转化,但是如果每个阵列都进行ADC转化,成本会非常高,因为如果用了很多ADC会导致芯片面积变大,从而能耗较高。所以我觉得一部分可以进行模拟信号传递,一部分进行数字信号传递。
激活函数可以通过硬件实现,虽然也有人用单个器件激活函数,但现在的函数实现是基于CMOS。
补充问题1:完整运行一个AlexNET,能效比有多少?
吴华强:目前,还没有完整运行过一个AlexNET,下一个芯片或许会进行。之前芯片集成度规模只有几十万,预计下一个芯片的规模是几百万。经过讨论,现在几百万的规模是可以运行AlexNET,且讨论结果还可以,但还需要实际运行。
补充问题2:忆阻器只负责实现基本矩阵计算么?是不是还要配合其他方式进行输入输出?
吴华强:目前忆阻器的算法只有乘法和加法,整个计算特别适合进行矩阵计算。要配合别的输入输出,还有存储和编码这都是需要的。而且从硬件层面看,阵列是固定的,算法是千变万化的,需要用编译器或者算法支持把千变万化的网络层映射到固定阵列上。
三、好奇心是如何产生的?它内在的机制是什么,有没有办法度量它?
毕彦超:主流的认知神经科学上目前没有很好的答案。首先从对婴儿、儿童的研究上可以看到,人们对新异刺激有天生本能好奇。另外,不光是在人身上,在猫身上也存在好奇。其实,生物体进化过程当中对于外部世界刺激的反应,是很重要的进化产物。所有的生物体是不是有比较基本的好奇心?是什么样的时间范式?如何实现?是不是有不同种类的好奇心,我自己也没有答案。
胡晓林:这可能和神经科学的一个理论相关,叫预测性编码(predictivecoding)。大致意思是:人对于外在世界会有一个预测,但如果实际刺激或者实际发生的事情和预测不吻合,就会有一个偏差,而人会关注那个偏差。
毕彦超:如果把好奇心定义为要时刻关注外面的世界,进行预测,才能实现实际有效的识别和交互。那有可能有关系。
四、能否介绍一下人脑是如何进行多模态融合的?
吴思:多模态信息整合是大脑的一个基本功能。人为什么有五官?我们用它通过物理、化学和声音等信号来感知外界,其中,大脑负责融合这些信号。
从数学角度看,多模态信息整合的最好算法是贝叶斯推理。有意思的是,行为上已经证明大脑能进行数学上优化的贝叶斯多模态信息整合,另外,在神经数据上猴子实验也有证明,在计算模型上也得到了验证。
最近一个多模态解释模型的基本的思想是:各脑区有分工,分别负责处理视觉信号、听觉信号等,但同时这些脑区之间又有连接,这些连接编码不同信号之间关联的先见知识。这样多个脑区间通过信息交流,最终以并行分布的方式实现了优化的多模态信息整合。
五、神经科学里有从儿童发展或者跨物种比较的角度来研究学习是如何动态的塑造大脑神经网络的,比如小孩的大脑可能更接近全连接,后面逐渐被选择性的消除掉一些连接。这样一种模式对计算会不会有帮助?
毕彦超:对AI的借鉴的程度尚不清晰,但确实是一个宝藏。首先从婴儿认知的发展上,人们发现很多有趣的现象,比如机器学习一个词很难,但小孩在“语言爆发期”只要听到一个词一次就可以学会。因此,这种人类方式值得AI借鉴。
对于人脑来说,对于婴儿的大脑非难研究,因为需要考虑无损婴儿的方式有损的方式研究婴儿。最近随着无损的神经影像的发展,才开始有一些特别基本的认知,通过分析早产儿的大脑,发现大脑的发育过程是:先发展初级的感觉运动皮层,随后,网络当中的其他枢纽,例如额顶这些更高级的网络就开始慢慢发展。
六、突触可塑性可以看成一种局部优化规则,大脑是如何进行全局学习和调控的?
毕国强:研究学习或者可塑性,一方面是观察突触本身发生的变化,另一方面希望在全局尺度上或者环路尺度上观察可塑性是如何发生变化的,但这需要明确突触前后神经元的活动,任何一个需要学习的内容在整个网络里面以不同的神经元活动表达出来的时候,就会有相应的突触发生变化。
再者,全局尺度上还有神经调质的作用,比如说情绪或者是奖励的信号,受到奖励的时候大脑里多巴胺系统会对整个网络有全面的调控。但调控具体影响还有待深入研究,但是一个可能是让在这段时间受到影响的突触的可塑性变化更容易。这样就在全局尺度上可以把很多突触的变化协调起来。
七、信息专业的学生如果希望自己入门脑科学相关内容,应该从哪里入手?
吴华强:我自己入门的时候是读一本《From Neuron to Brain》的书。读的时候如果遇到很多名词,一定要通过网络等形式查询清楚。另一方面,有一些无法理解的内容,可以先搁置。
通过看神经科学类的教科书是一种好的途径,因为这些书里大部分是数学语言,同时又介绍一些神经科学的基础以及模拟的方法。
吴思:最好能进到一个课题组,多听报告,参与做具体的课题,这样才更有效。如果光看书,无法长久坚持。而且学的东西得不到应用,会产生沮丧的心情,导致放弃。所以找一个合作课题是最佳的方式。
毕国强:很关键的一点是看个人的坚持,你有多强烈的兴趣和你想花多大的力气。当然提到花双倍的力气,很多人就有双倍的力气,这些人可能就适合做这件事情。
唐华锦:确实建议很好,在具体团队或者项目里进行实践,确实能够提升成就感,不容易产生沮丧。中科院这一点做的很好,你们甚至强制要求人工智能和神经科学蹲点。还有浙大,“双脑”中心也是强调人工智能和神经科学结合成团队。另外,至少要找两个相关领域的导师,然后进行这方面的工作,效果会很好。
毕彦超:跨学科交叉非常有趣,但一定要有一个自己的基础(Base),某个方面的基础学扎实了才有能力在交叉学科中深入,否则特别容易“飘”在表面上。
八、树突需要像突触一样来训练吗?
吴华强:从实物上来讲,树突也是被训练过的,所以答案是:应该需要。但是目前的研究工作尚未进展到那一步,如何进行还需要多方面思考。
九、脑科学领域对常识的研究,有哪些资料可以推荐?
毕彦超:我们近期有一篇文章要在Neuron发表,是第一次有直接的证据,通过看先天盲人对颜色的知识,在人脑发现有两种不同机制的知识表征。我推荐给大家。
Wang, X., Men, W., Gao, J., Caramazza,A., & Bi, Y. (2020). Two Forms of Knowledge Representations in the HumanBrain. Neuron, 107,
https://doi.org/10.1016/j.neuron.2020.04.010
十、人脑中是否存在误差反向传播?
唐华锦:答案是肯定的,即一定是存在误差反传,比如肯定有全局信号、奖励信号,只是反传方式不一样,传统人工智能的反传是基于梯度下降,但是在神经科学里很难实现,因为要求对称的传播,我觉得是具体实验方式的不同,但是一定是存在的。如果对这个问题感兴趣可以看最近一篇论文“Backpropagation and the brain”(Nature Reviews Neuroscience,2020)。